Azure File Sync is a Swiss Army knife-type of service we can use for transition, replication of data, backup, disaster recovery — you name it. We will focus on the scenario where we can have the File Server data being synchronized to the cloud to more than one server, and that becomes interesting when you have two or more sites that need to provide consistent file access to your end users.
This kind of approach has several advantages, to mention a few: remove backup requirements on-premises, provides a disaster recovery plan, reduce operational cost (no more DFS or any on-premises technology to replicate data), data will be always available to the end users from their local File Server, and if a VM running as IaaS (Infrastructure as a Service) requires access to that data in the cloud we can take advantage of Azure files and connect directly to the Storage Account improving performance to access the data.
Azure File Sync has a simple architecture — cloud endpoints, which is the Azure File Sync service and server endpoints, which are the registered servers with the service. On top of that, we have Sync Groups, which combine one cloud endpoint with one or more server endpoints. All members of this group will receive the replicated data where the central location will be the cloud endpoint.
Current scenario and desired state
We can start this scenario with TORFS01 server, which is replicating some data to Azure using Azure File Sync. We are going to add a new server called TORFS02, which is part of the same domain on-premises, and all data changed on either File Server will be replicated automatically to the other server endpoints that are part of the same Synchronization Group.
We covered the deployment and configuration processes in the previous article, but here is a summary of the steps required to be performed on the new server (TORFS02) that will join our replication.
- Install/update the AzureRM module on the server.
- Install the Azure File Sync software on it and register the server in the right Azure File Sync service.
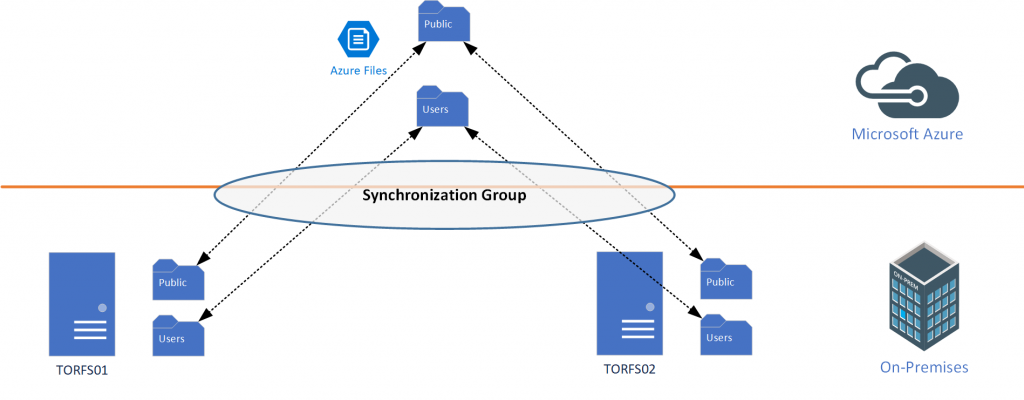
Having the server registered, we just need to list the existent Sync Groups item and click on the desired one. In the new blade, click on Add server endpoint. Select the new server that we have just registered, and define the path. (It is a good practice to always use the same physical path for the data because it will make troubleshooting much easier using a consistent setting across servers.) Click on Create.
Note: The new server endpoint does not have that path created (C:\home\public) and because the data is already in TORFS01 and Azure File (in the public File Share), as part of the provisioning of the new server endpoint in this sync group will create the path and synchronize the files.
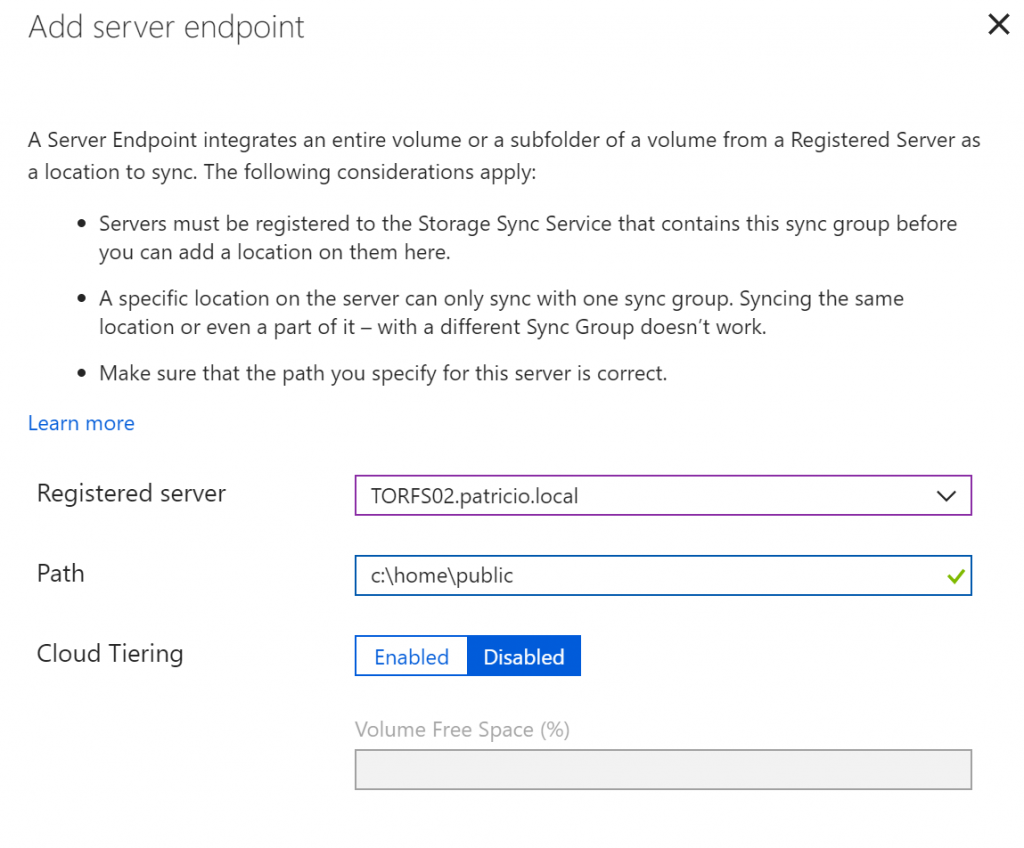
The result of the operation that we have just performed is going to be displayed in the Sync Group detailed page where we have two server endpoints, as depicted in the image below. We can see the status of the new server being displayed as Provisioning. Now it is just a matter of time to synchronize the data (data size and bandwidth play a big role on that process).
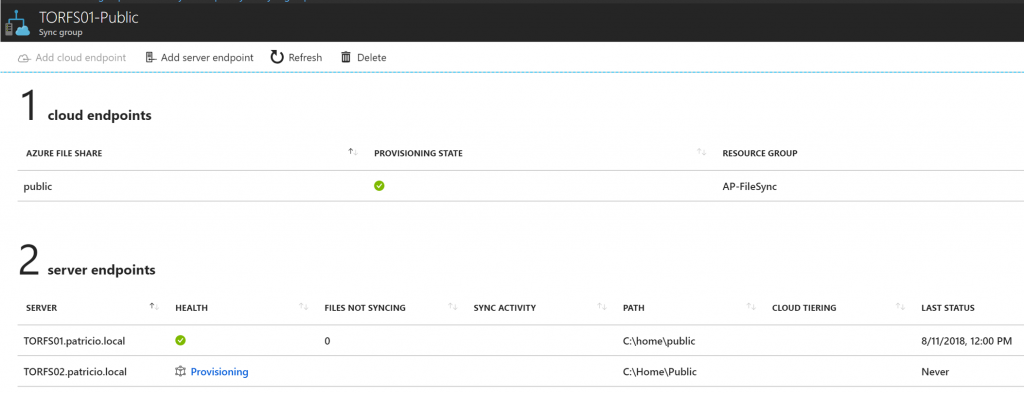
After a while, we can see that the structure was created (C:\Home\Public) and we do have data there, which means the replication is taking place and at the end of the process we will have the same data on all three locations: torfs01, torfs02, and Azure Files.
OK, I hear you asking, how about the NTFS permissions? It is preserved! In the example below, we check the properties of one of the files and we see that the NTFS are the same as the original.
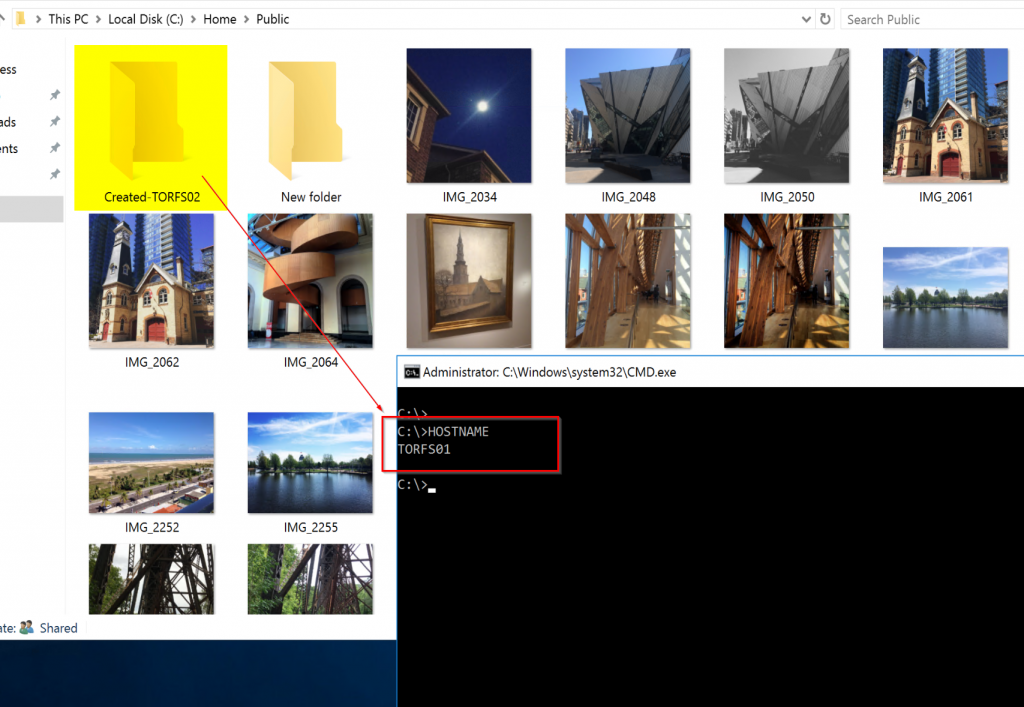
Since we are on TORFS02 we are going to create a new folder called Created-TORFS02, and we will check if the replication occurred.
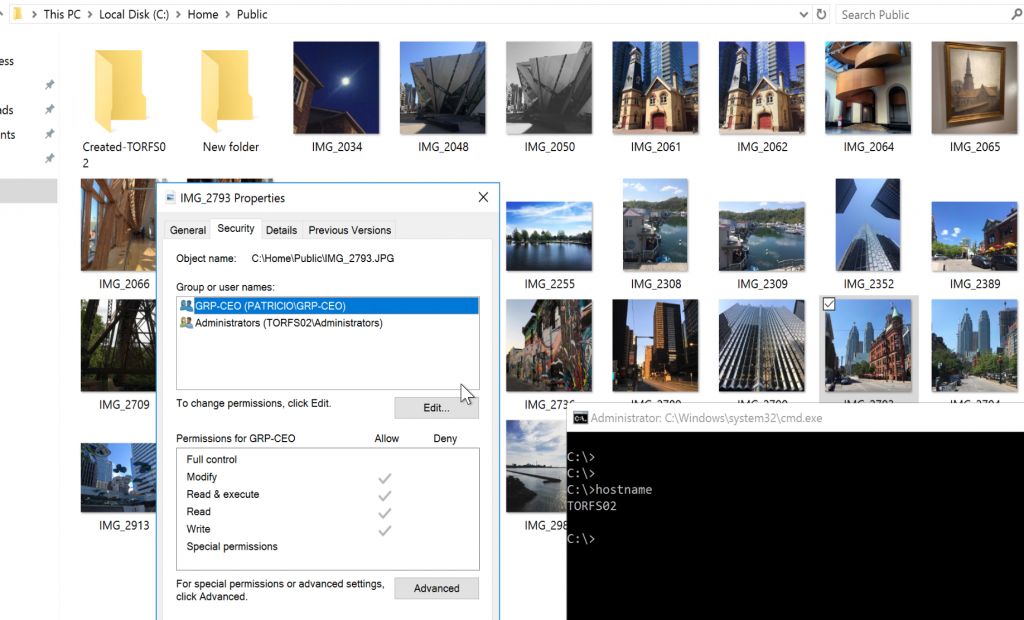
Now, logged on TORFS01, we can see that the folder that we created on the server TORFS02 was replicated and it is available on this server as well. That is fantastic!
Protecting your file server data in Azure files
There are a couple of ways to protect your data. The most important one is a proper design of your Storage Account, and the recommendation for important data is to use GRS (geo-redundant storage), which provides 99.99999999999999 percent of durability of objects in a given year (yeah, that is a lot of nines!). It works by having an LRS (Local-Redundant Storage) committing the information on the first region, and then sending the information asynchronously to another region.
Besides the protection at the Storage Level, we can take advantage of Snapshots. We can create them at the File Share level and they are limited to 200. They do not impact the performance and they are stored on the same Storage Account of the data, which means that they obey the same laws of you replication type (GRS, ZRS, LRS and so forth).
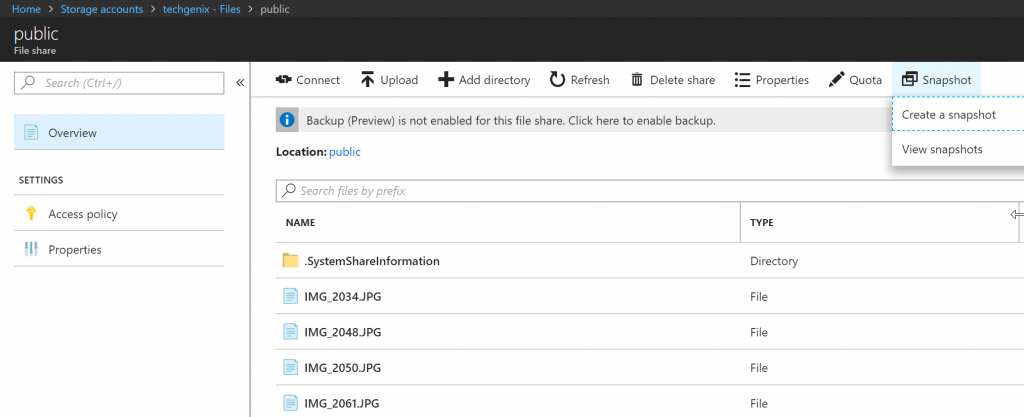
To create a Snapshot, open the Storage Account, click on Files, select the File Share from the list, and click on Snapshot and select Create a snapshot to create one or to see previous snapshots click on View snapshots.
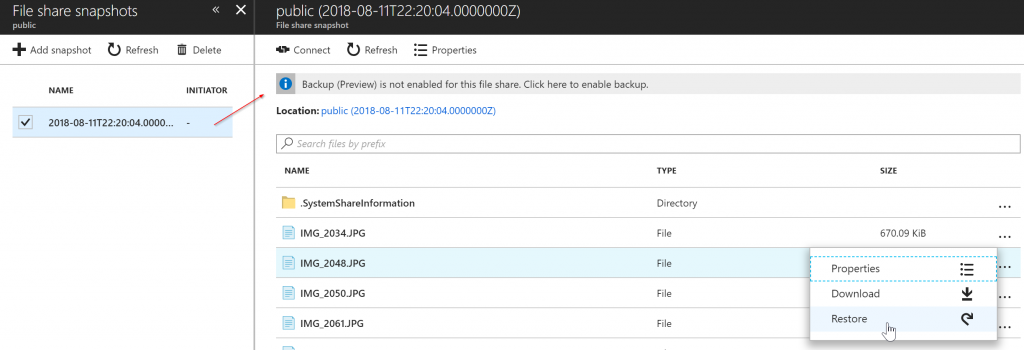
If a file was deleted by accident, just click on Snapshot and then View Snapshot. A new blade containing all snapshots will be displayed, select the desired snapshot, select the desired file and click on Restore.
Note: If you feel more comfortable connecting to the snapshot and retrieving information at your own pace using Windows Explorer, you can always use the button Connect, which will list the required cmdlets to be executed to connect your chosen machine/server to connect to that specific snapshot.
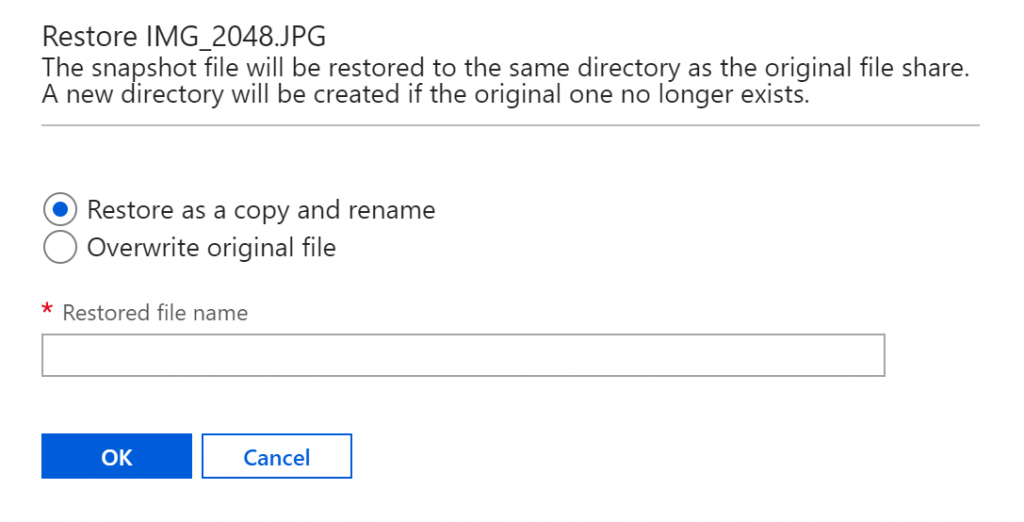
The restore option allows the restore of the file with a new name or overwrites the original file (if it exists).
An alternative to Azure File Sync?
Another possibility is using Azure Backup. We will cover that in details in a separate article here at TechGenix.




Nice article. What about conflicts from one server endpoint to another? If I have two users opening the same file at the same time but from different endpoints what will happen there?