If you would like to read the first part of this article series please go to Collecting Threat Intelligence (Part 1).
Introduction
In the first article in this series I provided a definition for threat intelligence and some basic techniques for gathering information on domains and IP addresses. In the conclusion to the series I’m going to talk about a few other resources for gathering threat intelligence and some tactics for effectively using Google to learn more about addresses of interest. Lastly, I’ll hit on a few techniques that you need to use in order to ensure that your research doesn’t get you into any trouble.
DNS Records
The Internets reliance on DNS is a double edged sword. DNS is fast and flexible but its distributed nature and its reliance on making certain bits of information public can help network attackers and defenders alike. One of the simplest ways to garner useful information about a potentially hostile target is to enumerate the DNS records associated with it.
Continuing with the same tactics we’ve used previously, we don’t want to reach out and touch a DNS server that is potentially under the control of a hostile entity, so a third party service is necessary. I’ve always been fond of network-tools which allow for DNS queries along with a few other things. By selecting the DNS record option you can provide an IP address or domain name and get the DNS records associated with it. This will include records such as A, NS, MX, etc. records. Doing this will help you quickly build up a list of associations to other domains, IP addresses, and networks. In this case, the IP or domain you started with may not be able to be attributed to anything malicious, but one of the associated entities may be. Guilt by association can be a viable and valid thing.
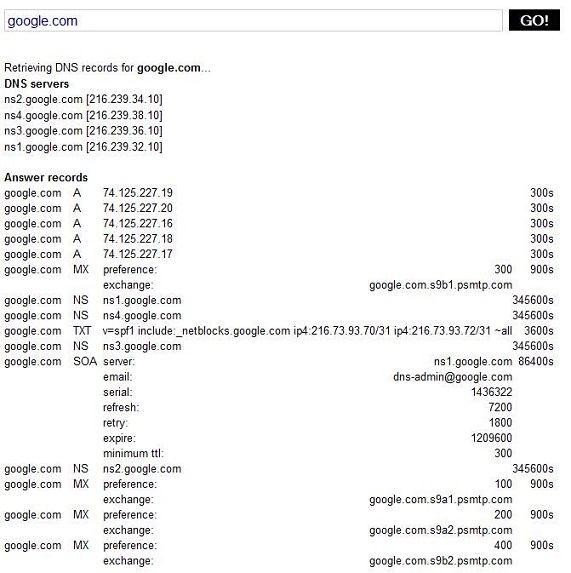
Figure 1: Performing a DNS query using Network-Tools
Blacklists
Whenever an IP or domain does something bad with e-mail you can guess that it’s likely it will end up on a blacklist. E-mail spam filtering services rely on blacklists in order to ensure that junk mail doesn’t find its way into your inbox. These blacklists can be valuable for the purpose of evaluating potentially hostile targets because they indicate hosts who have previously or actively been used to generate spam.
There are several blacklists that various vendors reference and because of this it’s a good idea to use a website that queries multiple blacklists instead of checking them individually. You can perform this task here, but when I want to be thorough I use this site, since it checks more blacklists and has some other useful e-mail specific tools.
An important thing to keep in mind here is that it’s incredibly easy to end up on a blacklist. Even legitimate servers end up in these lists from time to time so although blacklists are good indicators they aren’t something to be trusted fully and as a result shouldn’t be relied upon as a single source of threat intelligence.
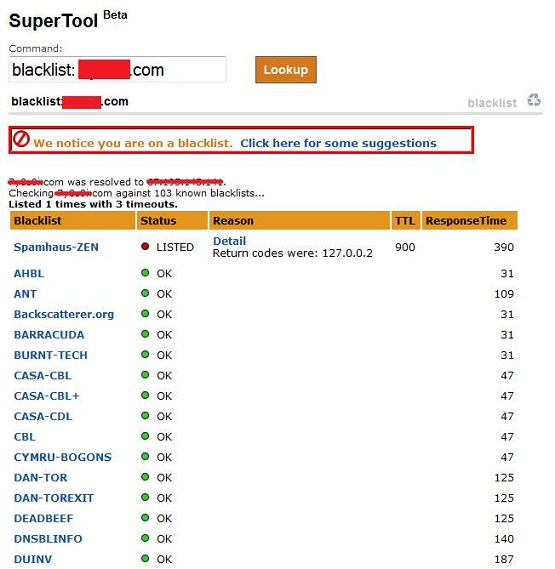
Figure 2: Checking blacklists at MX Toolbox
The most powerful tool at your disposal is the ability to perform searches based upon the context of data you have. To that end, simple Googling an IP or domain may yield positive results. When the IP or domain alone doesn’t provide enough information then you will need to extend your seach by adding relevant keywords based upon what you are seeing.
For instance, if you are seeing an unusual amount of encrypted traffic on port 443 you could simple add “port 443” to your search string. If you are looking at weird HTTP GET requests for a particular file then you could add that file name to your search. The point is that you have to be able to take the data you have available in order to whittle down search results so that you can get something useful. Chances are you may not find anything but there is a possibility you may find where someone else is seeing the same traffic or find some other obscure lead that can help you determine if a host is hostile.
Aside from just throwing in search terms there are a couple of operators you can use that will help. These include:
- Site: The site operator restricts your search to a specific domain. I’ll use this frequently when I’m searching for potentially hostile data within a known legitimate domain. One example might be searching for an embedded iframe that has been injected into a legitimate website. Additionally, you can use this to map out all of the pages indexed for a single domain.
- Filetype: This operator tells Google to only return results that match the specified file type. This is really useful for finding out more about PDF files that may contain embedded malware. Performing a search using the site and filetype keywords you can enumerate all of the PDF files contained at that site. You can then perform searches on the other PDFs you find to see if they show up anywhere that identifies them as malicious. Try plugging the results you find into something like ThreatExpert.
- Inurl: This one searches only within the URL of sites Google has indexed. If I see an HTTP GET request that looks a bit odd I’ll plug pieces of the URI into this operator to see if it appears on other sites as part of something evil.
There are thousands of useful searches you can do using the operators within Google. As a matter of fact, there are so many that some people have devoted a significant amount of research to this. One of the better known resources for Google hacking is Johnny Long’s book, Google Hacking for Penetration Testers. Additionally, you can reference the Google Hacking Database here, which is also a Johnny Long creation. Using some of the techniques found in those resources you can find the versions of software running on web servers, find directory listings, and even automate some common intelligence searches. Having some level of Google Hacking skills is required for any effective computer defense analyst.
Having Powerful Friends
When all else fails one of the most effective things you can do is seek out help from other sources. Part of this relies on having industry contacts outside of your organization that are in similar roles. Using those people you can build a network of individuals you trust that you can share information with regarding potential hostile entities. At the very least it helps to be able to IM a friend and describe some weird network traffic you are seeing in order to see if he/she is seeing something similar. I can’t count the number of times this has provided me valuable insight in critical times.
Along with individuals, user groups, blogs, IRC channels, and the like are great tools at your disposal. One more powerful resource at your disposal is the SANS Internet Storm Center (ISC). The ISC is staffed by volunteer handlers who are on call 24×7. These handlers are top notch intrusion detection specialists. The ISC provides a contact form you can use to submit interesting traffic that handlers can analyze. A diary style blog is also kept here that discusses security trends and new information relevant to network defenders. You can read more about the ISC and its handlers here.
Protecting Yourself
In the first part of this series I mentioned the importance of protecting yourself and not communicating directly with potential attackers. There are a few things you can do in order to ensure you are protected:
Cached View
When performing searches on hostile entities you may be tempted to browse to associated site to see what content is there. Generally, this is a bad idea, especially on a computer connected to your production network. One technique that can be used here is to use Google’s cache to a view an archived copy of the site that is not actually contained on the potentially hostile host. If a cached version of a page is available then you should see a “Cached” link in the search result listing that you can click. Keep in mind that when viewing a cached page, clicking a link on that page will follow the link to the actual host it is stored on, not a cached version of that page.
Prefetch
Link prefetching is a browser feature that allows browsers to automatically download web content based upon links the browser predicts that you may click. These predictions are made based upon code in websites. As you can imagine, there may be some website you visit that you don’t want automatically downloading content on your behalf. That being the case, I always disable prefetching on whatever browser I’m using and would recommend the same for you if you are doing threat intelligence research. Disabling prefetch is a browser specific setting so you will need to research how to do this based upon the browser you are using.
Conclusion
The tactics, techniques, and procedures that attackers use to penetrate our networks will continue to change on a minute by minute basis. Given the proper defenses it is very possible that we have all of the data we need to make informed decisions about unknown systems that are communicating with our network. As a defender one of the most important decisions you can make is the determination of whether or not a host is hostile. If you make the right decision then a crisis may be averted and if you make the wrong one then you may be looking for a new job. My hope is that this article has provided some useful tips for performing threat intelligence research and will help you in making that crucial decision.
If you would like to read the first part of this article series please go to Collecting Threat Intelligence (Part 1).



