One of the big IT trends over the last several years has been a major emphasis on disaster recovery and continuity of business planning. Shops of all sizes have been evaluating their IT disaster recovery capabilities in the hopes of being able to keep everything online in the event of a disaster.
The concept of disaster recovery has, of course, been around seemingly forever. Way back in 1992, I remember helping the organization that I worked for complete a disaster recovery test. Even though disaster recovery is nothing new, there are several things that have caused disaster recovery planning to receive much more emphasis than it once did. Some of the contributing factors include:
- The public cloud can act as a failover site, which eliminates the cost of building a remote datacenter.
- Virtualization has made it possible to failover to another server, or to another datacenter with minimal effort.
- Backup software now supports instant recovery capabilities.
- Operating systems, hypervisors, backup software, and the cloud have all evolved to the point that disaster recovery capabilities are financially within reach of almost any organization, whereas such capabilities were once available only to the largest companies.
- In at least some cases, regulations have mandated the need for disaster recovery capabilities.
In spite of all of the IT disaster recovery planning that is going on, there is one really big thing that almost every organization misses. Many IT experts will tell you that the most overlooked aspect of disaster recovery is testing. While I don’t dispute the idea that disaster recovery testing is often neglected, there is another factor that is perhaps even more important, but that I have never heard anyone mention. That’s the human factor.
Don’t get me wrong. The human factor does get addressed to a point. A list of key personnel and their contact information should be a part of every disaster recovery plan. However, there is something else that is missing. Rather than just telling you what it is that everyone forgets, let me paint you a picture.
Let’s pretend that an imaginary company has its headquarters in Portland, Ore. Let’s also assume that everyone on this company’s IT staff is intelligent, well educated in all things IT, and hard working. Not surprisingly, they have meticulously created and thoroughly tested a disaster recovery plan that will allow all critical systems to automatically failover to another region in the event of a disaster.
Explosive scenario

Now let’s pretend that one day Mount St. Helens has a major, but somewhat unexpected eruption. The eruption isn’t sufficient to destroy Portland, but it does make a mess of things.
Just to make things interesting, let’s also pretend that all of the seismic activity from the volcano causes Mount Rainier to explode within days of the Mount St. Helens eruption (it’s unlikely that both volcanos would go, but it could happen). Because everyone was keeping such a close eye on Mount St. Helens, the Mount Rainier eruption catches everyone by surprise. The Mount Rainier eruption ends up being a paroxysmic eruption with a Volcanic Explosivity Index of 5 (one notch above a cataclysmic eruption, and roughly on par with the 1980 Mount St. Helens eruption. This eruption and a resulting tsunami devastate Seattle and completely destroy areas closer to the mountain. Portland doesn’t suffer any damage from pyroclastic flows or from lava, but the city is paralyzed by ash fall and accumulation.
Obviously, I have painted a pretty bleak picture here, but let’s assume that all of the company’s employees have survived. So let’s talk about the aftermath of this situation. Even though the damage in Portland is fairly minimal, the ash fall could potentially lead to widespread power failures, causing our imaginary company to initiate its disaster recovery plan. Upon doing so, all of the workloads automatically failover to another region and remain online and undisrupted. Because the company’s disaster recovery plans have been so thoroughly tested, the entire failover process works flawlessly. So everything is good, right? Not quite.
Successful failover is not enough
Having a successful failover and uninterrupted functionality seems to be the end game for most IT disaster recovery plans. As ideal as this outcome may be, however, it overlooks something very important — the employees. In this imaginary situation, the company’s workloads continue doing exactly what they are supposed to be doing. Meanwhile, the employee’s lives are in turmoil.
Even though all of the employees survived this imaginary disaster, life is not exactly peachy for them. At best, the ash accumulation makes transportation difficult just as it did in 1980. Breathing has also become hazardous. More importantly, Seattle has been decimated. Given Portland’s proximity to Seattle, most employees probably have friends or family that did not survive the blast. As if that were not enough, such a catastrophic situation could also be enough to cause major economic problems.
Being that the employees are dealing with all of these things, what do you think the odds are that they will continue doing their jobs as if nothing had happened (even if that means working from home)? There are likely to be a few workaholic employees who are super dedicated to their jobs, and who will keep on working right through the disaster. For everyone else though, getting their families through the catastrophe will undoubtedly be their priority.
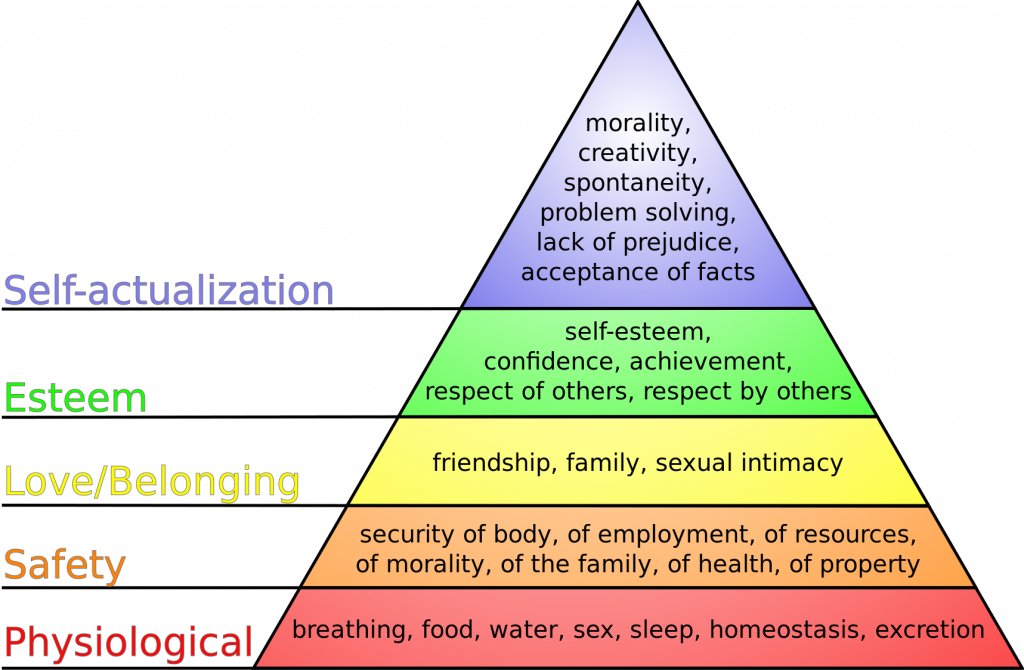
The tendency for employees to look after themselves and their families before worrying about the company’s needs was predicted long ago by Abraham Maslow, who created Maslow’s Hierarchy of Needs. Maslow’s Hierarchy of Needs (see the chart above) is a philosophy that essentially states that a person has to have their most basic needs taken care of before they can focus on other things. While it is easy to get bogged down in the details of Maslow’s theory, there is a really easy way of getting down to the essence of what Maslow describes. Imagine for a moment that you are scuba diving and you run out of air while under 100 feet of water. What are you going to be thinking about at that moment? Are your thoughts going to be about how to get that project finished at work, or are you going to be too preoccupied with thinking about where your next breath is going to come from? That is what Maslow’s Hierarchy of Needs is all about, and I think that it’s safe to say that Maslow’s hierarchy should definitely be a consideration when formulating a disaster recovery plan.
The bottom line is that if a major disaster were to happen, employees would almost certainly be focused solely on meeting their own basic survival needs. In such a dire situation, few if any employees are going to give so much as a second thought to the company’s IT disaster recovery operations.
IT disaster recovery starts with your employees
If it is true that employees probably won’t care about IT disaster recovery operations following a major disaster, then the organization must consider how it can ensure that the necessary staffing resources are available in times of crisis. Most of the organizations that I have worked with fail miserably when it comes to this part of the process because they equate the possession of an employee contact list with the availability of staffing resources. It never occurs to them that employees might not answer the phone when called upon, or worse yet, might tell their boss to take a flying leap.
The best way to ensure that staffing resources will be available in times of crisis is to borrow a page from Maslow’s playbook and formulate a plan for ensuring that employees are taken care of in times of crisis. Providing for the basic needs of the staff and their families during a crisis should be a key part of any IT disaster recovery plan.
Featured image: Shutterstock



