Enough has already been said about how the field of logging and monitoring has changed from the old days when it actually meant you could sit around and stare at a monitor. With microservices and containers firing away at speeds and scales incomprehensible to most humans, monitoring has taken on a whole new dimension. As more organizations continue to make the transition to a microservice architecture, the shortfalls of traditional logging and monitoring tools are becoming more evident. In response, what we’re now seeing is a new breed of APM, logging, and distributed request tracing tools that are slowly and steadily making their way to monitoring Kubernetes and cloud environments.
Glasnostic
Founded in 2013 in San Francisco, Glasnostic focuses on helping teams manage the chaos that comes from endlessly growing landscapes of connected applications that extend across platforms, clouds, and devices. These are referred to as “organic” environments that are usually characterized by being widespread and constantly evolving. According to the folks at Glasnostic, host-based monitoring just doesn’t cut it anymore since it’s ultimately the interactions between microservices that determine performance. While you can call it a control plane or even a cloud traffic controller, it’s actually a pretty neat way to monitor microservices for performance and availability.
It’s not just about visibility with microservices, but actionable visibility with predictable outcomes, if the aim is to have complete control over your environment, that is. Glasnostic achieves this by managing the complex emergent behaviors of microservices that typically manifest themselves as unpredictable events. These could be low latency periods, bursts, imbalanced interaction characteristics, or a number of other surprises that occur when time and scale are not accounted for as catalysts. The folks at Glasnostic also believe Istio will soon be a standard feature of Kubernetes, causing the service-mesh category to disappear altogether.
OverOps
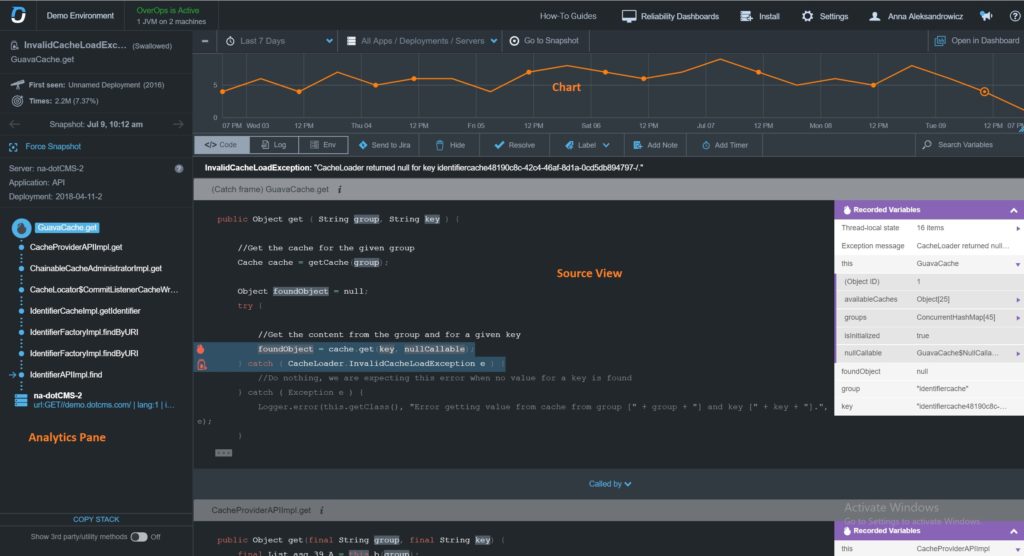
Another San Francisco based organization, OverOps, founded in 2012, is helping users deal with the new speeds at which updates are expected to arrive. Frequent code changes are a major contributing factor to broken Kubernetes applications, and OverOps aims to fix that by monitoring and analyzing code for anomalies at runtime and ensuring the right personnel gets notified if any do occur. An exciting and useful feature of OverOps is the automated root cause (ARC) screen, which, as the name suggests, gets to the root of the problem and displays it along with its source code, variables, debug logs, and container state.
To further emphasize this focus on code analytics during the application development process, OverOps partnered with SonarQube, a provider of static analysis tools for source code, earlier this year. Among other benefits, this allows issues identified by the OverOps plugin to be viewed and queried via the SonarQube dashboard, which is a lot more detailed and helps users save a lot of time finding the root cause of an issue. As DevOps teams continue to churn out code faster than they ever have before, OverOps aims to equip them with tools that not only ensure quality but also save time by reproducing issues a lot quicker.
ChaosSearch
ChaosSearch was founded in 2017 in Boston and is a multi-API, fully managed log analytics platform that stands out in the Kubernetes monitoring crowd in a number of ways. If you can look past the name and the fact that it only works on AWS, the ability to analyze, index, query, and log data directly on your S3 instances is pretty neat, to say the least. ChaosSearch accomplishes this feat with the help of its data edge technology that can turn a regular S3 dataset into a high-performing, ELK-compatible cluster.
Another factor that’s unique here is that data is analyzed, processed, and queried where it lies, and no actual movement of data takes place. What this means is that if you have a few terabytes of data lying around in your S3 storage, you can now instantly have it intelligently searched and analyzed at a fraction of the cost of ELK. In fact, CTO Thomaz Hazel was quoted stating this costs about 80 percent less than an ELK stack. In addition to being fully integrated with Kibana, ChaosSearch also enables machine learning-based insights and predictive analysis.
Lightstep
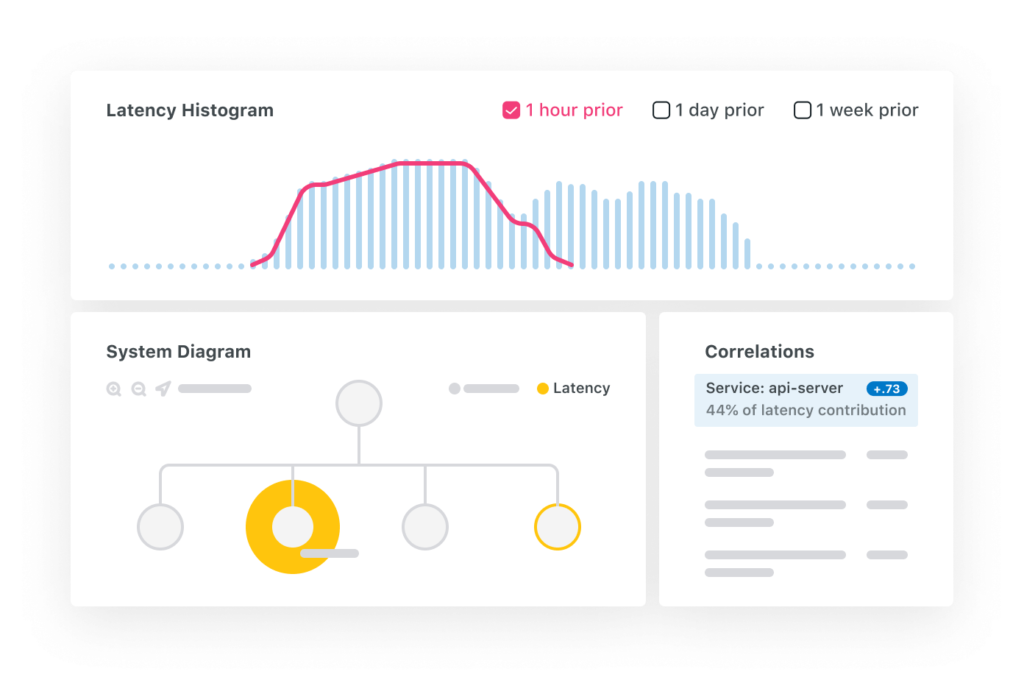
Yet another San Francisco-based startup on our list is Lightstep, founded in 2015, and making headlines in the field of distributed tracing ever since. Microservice and serverless architecture both suffer from a lack of visibility, making the job of searching for the root cause of an issue a lot like looking for a needle in a haystack. This is because modern distributed environments can have issues with transactions that span across a number of different microservices. Distributed request tracing not only provides end-to-end visibility across those interactions but also provides valuable insight into service dependencies.
Lightstep announced in June that they were making major changes to the distributed tracing platform to include features like log analysis and top changes to help users save even more time. Top changes makes use of Lightstep’s automated intelligence algorithms to quickly identify the most recent changes that are causing unwanted occurrences, Lightstep claims the new features can help customers zero-in on a single line of code as the potential cause of an issue in under a minute. This stems from the core functionality of this particular startup, which is to trace individual requests accurately across modern distributed environments.
Humio
Humio, a London-based startup founded in 2016, tackles the problem of logging by allowing users to log all data, structured or unstructured, in real-time, at scale, and with time stamps. Humio achieves this by offering users a time-series, live observability platform, with no upper limit on event analysis. What this literally translates to is an all you can eat buffet for logs with real-time analysis. In addition to being deployable on any infrastructure, including public clouds and on-premise, Humio also features innovative data storage facilities as well as built-in search engine technologies.
Humio was built from the ground up to log data as and when it’s ingested, and it seems to be doing that pretty well. Earlier this year, Humio announced it had raised €18.5 million in its Series B funding with the majority of investment coming from Dell Technologies Capital and Accel, which brings total investment close to €30 million so far. With a sharp focus on real-time observability and unrestricted log analysis, Humio provides value for money right out of the box. Deepak Jeevankumar, managing director of Dell Technologies Capital, was quoted stating Humio ingests and analyzes logs at a fraction of the cost of existing technologies.
Off to the races: Cloud and Kubernetes monitoring have more room to grow

As technology keeps evolving and these organic landscapes that we call environments keep expanding to accommodate new arrivals, expect this cloud and Kubernetes monitoring space to get a lot more crowded. Deploying microservices without the right visibility is like playing a game of cards blind, except you’re playing against a thousand microservices that are a lot quicker than you. Additionally, with the advent of 5G and the amount of information being collected from IoT sensors across the world, making sense of these enormous amounts of data is going to be critical and impossible without innovations like the ones from the startups mentioned above.
Featured image: Pixabay



