I find Exchange server to be a very complicated system and as in most complicated systems the most “trivial things” may bring it to its knees. One of these “trivial things” is lack of disk space on the disk that holds the log files for a specific storage group. When the Information Store identifies lack of disk space for a storage group’s logs it will dismount the stores inside the respective storage group.
The last sentence I wrote may sound very calm yet when this happens on one of the Exchange servers you are responsible for you will be anything but calm. Once the stores in the storage group are dismounted, users are disconnected from their precious information (mail, calendars, contacts…) and they will come waving pitchforks…
Before we delve into our main subjects I think it is important to understand the exact role that log files have.
Describing the Exchange storage system
A very oversimplified analysis of an Exchange server may state that that an Exchange server is nothing more then a database server that has some exotic extensions through which users can manipulate their data. This analysis (even though oversimplified) is not far from truth, and it emphasizes the importance of the database that stores the user’s information on an Exchange server.
Exchange server uses a database technology called ESE (Extensible Storage Engine), this database technology is based on the JET (Joint Engine Technology) database engine.
The ESE engine employs several files upon which the database is built (I have only specified the ones that are relevant to our topic):
- Store files– The store files hold the information that is already committed to disk. Each Exchange store (Private and Public) consists of two files:
- EDB– Rich-text database stores information in a proprietary format called Microsoft Database Encapsulated Format (MDBEF) that is submitted by MAPI clients.
- STM– Native Content Database holds all data that is submitted by non-MAPI clients.
- Transaction Log files– the log file stores altered data before it is committed to the database. A set of log files is unique to a storage group. The log files name begins with a prefix that identifies the storage group they belong to- E00XXXXX.log (belongs to the first storage group). The suffix for each log files name is a hexadecimal sequentially assigned number.
The active log file for a specific storage group is always called: EX0.log (X represents the storage group), once it is filled (5MB) it is renamed using the next sequential hexadecimal number and a new EX0.log is created. Since by default log files are not erased (by default storage groups do not use circular logging) the space on a log disk will eventually be depleted. The standard procedure for removing unused log files is backing the system up (full or incremental).
As mentioned earlier the size of a log file is 5120KB, if you find that the size of the files is different you may be looking at a corrupt log file.
Each set of log files has two placeholder files called: res1.log and res2.log. These files are used by the storage group when it runs out of disk space to store altered information before dismounting the storage group. - Checkpoint File– The checkpoint file is used to track which transactions have been committed to the database and which transactions have to be committed to the database. The name of the file is EX0.chk (X stands for the storage group) and its size is 8KB.
Using the files described above the ESE engine builds a transactional database. You may have noticed that during the description of the checkpoint file I mentioned transactions without explaining their essence, so to repay this debt here we go: a transaction is a set of commands that are regarded as one logical unit- they must all succeed or fail (as a unit).
The classic example for a transaction is a funds transfer in a bank:
- A bank client gives an order to move funds from account A to account B
- The money is deducted from account A
- The money is added to account B
If there is a failure in the process before the money is added to account B the whole event is considered as failed and it is rolled back – so no money is lost. In other words the whole transaction must succeed or fail as a unit.
The following steps describe the events that occur when data is committed or changed in the store:
- A user changes an item that is stored in Exchange’s data store.
- The relevant information (the information that has to be changed) is loaded into RAM.
- The information is changed in RAM and simultaneously written to the log file(s).
- At predefined time intervals the “new data” is flushed from RAM to the database.
After the data is flushed the checkpoint file is updated to indicate which log files are no longer needed since the transactions they represent have already been flushed to the database directly from RAM.
Based on the preceding description of how the database engine functions the importance of log files is in keeping the database in a consistent state.
If the database terminates in an abnormal way while a transaction is in progress or while “dirty pages” (data that has been changed and not yet committed to the database) still exists in RAM, the next time the database is mounted it will go through a soft recovery process.
Soft recovery causes uncompleted transactions to roll back and uncommitted data to be committed to the database.
So, as you can see log files play a very important role in protecting the consistency of your Exchange stores. When the system runs out of disk space on a log disk it will dismount the respective storage group(s) to avoid the possibility of inconsistency being caused.
The symptoms
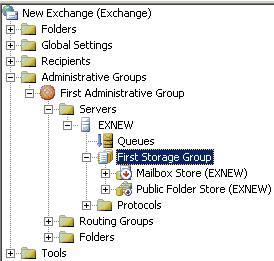
The symptoms for a full log disk are quite obvious, first of all, all of the stores inside the storage group will be dismounted:
Fig. 1: All stores in the storage group are dismounted
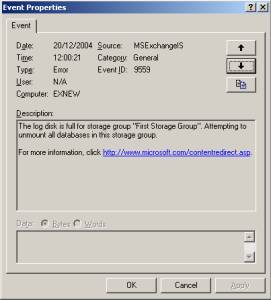
The second symptom will be a lot more descriptive – when looking at the Application Log you will find Event ID 9559:
Fig. 2: Event ID 9559
Preventive measures
The best way to deal with the loss of disk space on a log disk is not to deal with it at all – simply try to prevent it. If the storage group has already been dismounted because of lack of space, you as a system administrator have failed to protect your system.
You may receive some lenience from the court since at times the loss of disk space may be caused by a group or individual that is trying to maliciously disrupt the messaging services you provide to your company by sending huge amounts of data to your recipients (a.k.a. mail-bombing).
So at this stage you must be asking yourself how do I prevent this awful fate that awaits me???
In the upcoming sections of this document I will try to provide a few tips and tricks that may help you.
Preventive measures – Be vigilante
If the space on your log disk is near depletion you should know about it. If you are vigilant enough and you identify the problem while it is building up you can take steps to prevent it altogether.
Basically your weapon of choice can be any of the following:
- Check the disk space every few hours or at least once a day manually. The advantage of this option is that you do not need to invest in any monitoring service, thus you are not lowering your budget. An additional advantage is that you are not hampering server performance by running a monitoring service against it. The disadvantage is quite obvious – you have to do it… Now you may be a very productive system administrator but you are human so you may forget to check the space from time to time and the attack on your server may happen at night while you are fast asleep.
- Use a monitoring service. This solution is an automatic solution that will monitor the system and raise an alarm once a problem is found. There are many monitoring tools on the market from which you can choose and one of them is built into the operating system (Performance Monitor). Perfmon will do the job after you configure an Alert (with a threshold of 30% available disk space) and best of all it’s free.
In addition you can monitor the System Log for event 2013 (warns about low disk space). This warning actually tells you that your disk drive has reached a threshold of 10% of free space or lower. This threshold can be changed by editing the registry as per knowledge base article 112509.
Looking into the abyss
So you were vigilant. Your systems raised the alarm and you are ready to leap into action – what do you do? Well as I said earlier if you received warning about your disk space getting depleted there are two courses of action that can be taken:
- Run an online backup (Full or Incremental)-backing the storage group up using either of the aforementioned methods will remove the unneeded log files providing you with extra disk space.
- Advantages– Your system is backed up. If the system crashes later that day you can restore to the exact point in time it crashed (if the new logs created after the backup survived the crash).
An additional advantage is that by using this method there is no downtime and your user community will be pleased. - Disadvantages– The backup process may take precious time which you do not have. If the log files will not be pruned before you run out of disk space you stores will dismount.
- Advantages– Your system is backed up. If the system crashes later that day you can restore to the exact point in time it crashed (if the new logs created after the backup survived the crash).
- Turn on Circular Logging for the storage group– Before you scream and shout I do understand that I am walking on thin ice here – but drastic situations call for drastic measures. By turning on the Circular Logging option for the storage group while the stores are still mounted the log files will be pruned and only five log files will remain. Turning on circular logging can be done by accessing the properties of the storage group and by checking the option called “Enable circular logging”. Read and acknowledge the warning that appears and you are done – watch the log files disappear.
- Advantages– The only advantage here is time. This is the fastest solution for the problem.
- Disadvantages– Circular Logging will take away your ability to restore the system to the point in time at which the server crashed.
Fig. 3: Turning on Circular Logging.

And then came the rain
It is inevitable- rain will eventually come, so you really should walk around with an umbrella…
If you have passed the threshold and your stores are down your most important task is to renew service to your messaging clients.
Prepare for a rainy day
In our case preparing for a rainy day means saving some disk space. If your log files get out of control release the disk space you saved and presto – you have a few more minutes/hours of grace to take care of the problem…
I saw this method being practiced by many messaging administrators. They copy a large amount of data onto their log disk (approximately 10% to 15% out of the disk’s space) and when they start running out of space they simply erase the files. By erasing the placeholder files the system administrator allows himself some extra breathing room until he solves the problem.
Another advantage of this method manifests itself once the disk space for your log files has been depleted. Most methods to fix the problem will take some amount of time during which your users have no access to their data. If you prepared ahead and you captured disk space, as I advised earlier, to get the system up and running all you have to do is to erase the placeholder files and remount the storage group. Once this is done, you can quietly contemplate on finding a solution for the problem at hand (for additional information read the section called “Looking into the abyss”).
Move the log files
If you have enough (actually more then enough, preferably a lot more) disk space to hold your log files on a different volume on the same system you can move them there. Once you moved the log files you can mount your databases. Since this is a temporary solution after you have your system up and running you should solve the problem by using one of the methods specified in the earlier section called “Looking into the abyss”.
A word of warning:
Before you choose this course of action be sure to consider the downtime your clients will experience. Depending on the total size of your log files it may take a long time to move them to the new volume. In addition keep in mind that eventually you will want to move the log files back to their original location – that means more downtime since moving the log files will automatically dismount the databases in the respective storage groups.
The path less traveled- Remove unneeded log files manually
As I already said earlier, drastic situations need drastic measures and this is the most drastic measure you can take.
Almost all Exchange administrators know and live by the golden rule: “Do not remove Exchange log files manually!”. Basically I agree. If you have any other course of action that may work for you when you lost all empty space on your system then use it before trying this one.
Users data in Exchange is stored inside Exchange stores which are homed inside Exchange storage groups that have one set of log files for all stores that are homed in that storage group. In a point in time users data may be spread out between the stores and the log files. To keep a store consistent all database files (EDB and STM) and log files that have uncommitted data are needed.
The only log files that can be removed manually are log files that do not contain uncommitted data. If a log file that is needed by one of the stores (contains uncommitted data) is mistakenly erased the store becomes inconsistent and un-mountable(restore time-woohooo!!).
At this point you must be asking yourself – how can I know which log files have been committed (and should be earsed) and which have not been committed (and should not be erased)?
There are two answers to your question:
- The Checkpoint file– as mentioned earlier the checkpoint file is used by the Exchange storage system to identify the point up to which log files have been committed to the stores. By using the ESEUTIL tool a system administrator can dump this information from the checkpoint file (Fig.4).
The exact command used to dump the file is eseutil /mk <path to checkpoint file>.
The only information we are interested in is the line that looks similar to the following one: Checkpoint: <0xF,208,E2> . On this line inside the brackets you have three pieces of information of which only the first interests us- 0xF. The first piece of information points to the log file which is borderline, everything before it can be removed and everything after it is needed to keep the databases consistent.
In our case 0xF actually means that the log file prefix is E00 and suffix is 0000F. So the filename is E000000F.log .
Keep in mind that by erasing log files you lose the ability to restore the system to a point in time so my advice is to simply move the files to a different location, another benefit that is gained from moving the files is that if anything goes wrong you can always copy all log files back to their original location.
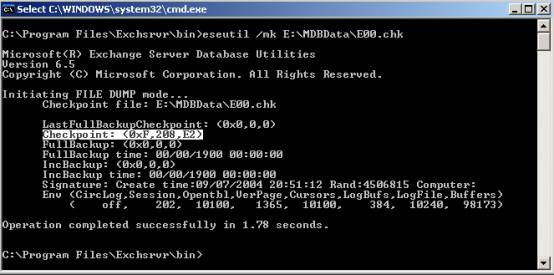
Fig. 4: Dumping the checkpoint file - The database files– Each database file used by the store contains information about the log files it needs to become consistent. To glean this information from the databases a system administrator has to use ESEUTIL again. The command slightly changes: ESEUTIL /mh <path to database file>. The output can be overwhelming but we are interested in two lines:
-
- State– this line specifies the database state which can be either:
– Clean Shutdown (fig. 5)– indicates that the database was dismounted in an orderly fashion or in other words it means that all outstanding transactions were committed to the database and it is consistent(no log files are needed to bring it to a consistent state).
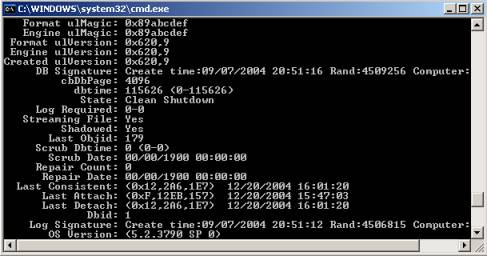
Fig. 5: Clean Shutdown
– Dirty Shutdown (fig. 6)- indicates that the database was shut down incorrectly – outstanding transaction from log files were not committed and the database is inconsistent. The next time the store is mounted the database files will need specific log files to become consistent-without them the store will not mount.

Fig. 6: Dirty Shutdown - Log Required – this lines specifies the log files needed to make the database file consistent.
– State: Clean Shutdown – the Log Required line will show 0-0, meaning no log files are needed.
– State: Dirty Shutdown – the Log Required line will show a range of numbers such as 17-19. This is the range of log files needed to bring the database to a consistent state (17, 18, 19). To identify the log filenames the numbers have to be converted hexadecimal, in our case 11, 12, 13 adding the prefix to it(based on the log prefix for the storage group) E0000011.log, E0000012.log, E0000013.log.
- State– this line specifies the database state which can be either:
-
Of the methods discussed I prefer using the checkpoint file. It is simpler and there is only one place to look as opposed to checking the database file where you have several places to check.
After identifying the committed log files they can be manually erased. As I said earlier I prefer copying them to a temporary location until I am sure that the storage system is working correctly. When you have enough space on the volume you can mount the stores.
In Conclusion
Don’t go there. The best way to deal with this problem is not to deal with it, you should try to make sure that you never run out of space on the log file disk – because if you do your clients will experience service outages. So – be safe and bring an umbrella!

