Introduction
Over the past number of years processor performance has doubled approximately every 18 months. This increase in processor performance, combined with multi-core technologies has driven the demand for higher data transfer rates. This data transfer needs to happen between an I/O device, memory, and between processors. In many of today’s computers the data transfer capability is the limiting factor for overall system performance. In this article I will highlight the details of one solution to this performance issue.
One solution for higher data transfer rates is called HyperTransport. Most users will recognize this from some AMD products. In fact, HyperTransport was invented at AMD (with help from some industry partners) although it is now managed and promoted by an independent group called the HyperTransport Consortium.
HyperTransport is a point-to-point interconnecting system focused on chip-to-chip communications. From its inception it has been designed to offer high speeds and low latency. This is a requirement today and into the future as CPU clock speeds continue to increase. Chip-to-chip communication especially demands low latency and high performance.
Being a point-to-point interconnect technology, as opposed to a bus system, offers many advantages for chip-to-chip communication. One advantage is that the communication signals do not require multiplexing. Also, these communication signals experience less interference and therefore experience less noise and can be transmitted with less power. This all combines for faster, and cleaner, communications.
Another advantage of a point-to-point technology is that it does not suffer from degraded performance, as PCI buses do, as the number of devices connected increases. HyperTransport utilizes a direct connection between two devices only. More devices can be connected only by utilizing a daisy chain method. This means that the performance is the same as more devices are connected.
Packet Based
HyperTransport is packet-based. This allows HyperTransport to play the interconnect role for many different purposes. This technology can be used to interconnect processing cores, RAM and CPU, or even external memory equipment. For more information on these memory types, see my previous articles on computer memory here, here, and here. Since the HyperTransport technology is packet-based, the hardware that is interconnected forms what most would consider a network. In the case of a super-computer having a network of processors interconnected with a point-to-point technology can be very beneficial.
Low Packet Overhead
Like most networks, a HyperTransport network will have performance characteristics. HyperTransport happens to measure up very well when its performance is compared against other interconnect technologies such as PCI Express. One reason that HyperTransport compares favorably to its peers is the low packet overhead designed into the technology.
HyperTransport required an 8 byte read request control packet for read operations. For write operations, HyperTransport uses an 8 byte write request control packet with and a 4 byte read response packet. This is it. That is all the overhead; 8 bytes for a read operation and 12 bytes for a write operation. PCI Express requires 20 to 24 bytes of overhead for its read and write operations. This is obviously a major advantage for HyperTransport.
But all is not perfect for HyperTransport. I need to be fair to the PCI Express technology here. With HyperTransport, the data packet which follows the control packet(s) can only be from 4 to 64 bytes. The data packet for PCI Express can be up to 4096 bytes. So, in some instances PCI Express can have a lower packet overhead than HyperTransport. However, in my opinion, and I don’t have any data to back this up, most read/write operations will require relatively small data packets; thus giving the advantage to HyperTransport. This is especially the case when we are talking about data transfers between processors.

Figure 1: A diagram of packet overhead for HyperTransport and PCI Express.
Courtesy of www.hypertransport.org.
Bandwidth
HyperTransport was originally designed to offer significantly higher bandwidth than other competing technologies. One way it does this is to provide a Double Data Rate (DDR). Normally when data is digitally transmitted between two points, data is read as either high or low which represents either a 1 or 0. This data is read whenever the clock produces a high signal. With DDR, data can be read on the rising and falling edges of a clock signal. This means that in one full clock cycle a DDR capable transmission data can be read twice, producing twice the data rate.
Low Latency
Low Latency is a design parameter which has been a focus of the HyperTransport technology since the beginning. HyperTransport can achieve this in part by having a single clock signal per set of 8 data bit paths. This is significant because other technologies, such as PCI Express, have their clocks embedded in a complicated encoding/decoding scheme at both ends of the data link. The method used by HyperTransport is effective in reducing the latency when compared to other technologies because the transmitting device does not need to spend time encoding the clock and the receiving device does not need to spend time decoding the clock.
Priority Request Interleaving
Another aspect of HyperTransport which contributes to its high performance is what they call Priority Request Interleaving (PRI). This is a really cool idea. Figure 2 below shows how PRI works. The problem PRI solves is this: When the CPU is in the midst of a long communication sequence with peripheral device B and peripheral device A needs to communicate with the CPU device A will normally need to wait until device B is finished communicating in order to proceed with its own communication; this can take quite some time and obviously reduce the overall performance.
PRI technology allows peripheral device A to insert a PRI packet into the data stream of device B. This PRI packet is read by the CPU which can then commence a communication sequence with device A on a different link channel.
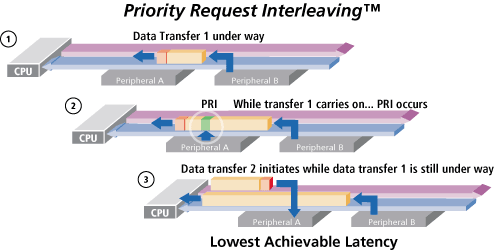
Figure 2: Diagram explaining PRI. Courtesy of www.hypertransport.org
The HyperTransport technology has been designed from the beginning to provide board level interconnects which allow for high communication speeds with low latency, high bandwidth, and high scalability. By all accounts it has achieved these goals. HyperTransport is used in many applications from the embedded market, consumer electronics, home computers, enterprise level networking equipment, carrier grade networking equipment, and even super-computers.
However, not all of these applications use HyperTransport in the same way. Some processors include HyperTransport technology right in the processor. Such processors include many offerings from AMD, Transmetta, Broadcom, and PMC Sierra. Other processors, PowerMac’s old G5 for instance, use HyperTransport as a high performance I/O bus that pipes data from PCI, PCI Express, USB, and other technologies through the system. HyperTransport provides excellent performance in both use case scenarios.
Conclusion
Although HyperTransport is an excellent technology with many performance benefits there is still a place in the market for other technologies. Engineers need to consider their needs carefully to choose the technology that is right for a specific application. In upcoming articles I will go into more detail on some of these other interconnect technologies.