In this article, we are going over the process of how messages logs are generated in a Linux server. We are going to use Red Hat Linux Enterprise (RHEL), which is my preference when working with Linux. However, most of the concepts can be used on a large variety of Linux even outside of the Red Hat family. Red Hat Enterprise Linux has two methods to analyze logs. The orthodox way is using rsyslog daemon, and that is the focus of this article. However, there is also a journald implementation that was introduced when the platform switched over to Systemd. We are going to cover this second method in a separate article.
When using Microsoft Azure and Log Analytics, it becomes crucial to understand what Azure is going to gather from your Linux VM when the monitoring agent is enabled, and we will learn all of this in this article.
Understanding rsyslog
When troubleshooting a Linux server, we have a particular folder that contains all the logs of the system, and it helps the Linux administrator analyze the logs.
This folder is called /var/log, and when we list the files there, we will find a variety of files containing log information of all sorts of levels.
There is a lot of useful information, and as Linux/cloud administrator, we should keep track and keep an eye on several of those files.

The first question that may come to mind is how to put all those pieces together, right? How do I know that my authentication log messages will be in a specific file? Are we missing something? The default values are pretty good for the vast majority of environments, but understanding where they are and how to play with them is critical for your security.
There is a central file that controls all the rsyslog operations in a given server, and it is called /etc/rsyslog.conf. The file has several sections, such as modules, filters, forwarding rules, and so far.
For this article, we are more interested in the rules section, and it is at that location that we define the facility, priority, and the file that will receive the log messages. The final result should use this following structure:
facility.priority /var/log/filename
OK, we understand the players now. The next stage is to see the variables available, and having a deeper knowledge about facility and priority will address this gap.
The facility is the first piece before the period sign (.) and corresponds to the subsystem that produces the log message. We can use numbers instead of those names. For example, kern messages are 0, and user messages are 1, and so forth.
- kern(0)
- user
- daemon
- auth
- syslog
- lpr
- news
- cron
- authpriv
- ftp
- local0 to local7
The second piece of the puzzle is the priority, and it ranges from 0 to 7. Here is a summary of the level with their caption and numbers that we can use instead.
- emerg (level 0)
- alert (level 1)
- crit (level 2)
- err (level 3)
- warning (level 4)
- notice (level 5)
- info (level 6)
- debug (level 7)
Now, we can look at the rules section of the /etc/rsyslog.conf, and it will make sense of the information that we have there.
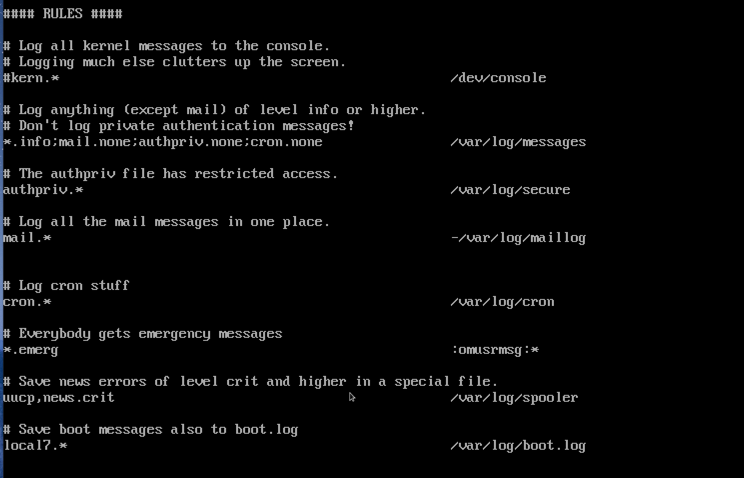
There are some rules when typing your rules. I will try to summarize here some golden rules that will help you when playing with that file.
- * is a wildcard and applies to everything, for example, all subsystem information will be logged (*.info), and all cron log messages will be recorded (cron.*)
- If you define a priority (*.info) that means that all priority info or higher will be logged (everything but debug level, because it has more information than info level)
- If you want to define just a single priority, we need to introduce an equal sign (=) in front of the priority (example: =info)
- If you’re going to exclude something, you can use an exclamation mark (!)
- We can use a semicolon (;) to separate a set of facility.priority in a single line (example: *.info;mail.none)
- We can use none in the priority to exclude the facility from the current rule
Rotating logs
We worked on managing what type of information we will store in our log files and how much data we are expecting (where debug priority generates much more traffic than alert priority). We need an efficient way to control disk space utilization, especially in systems that generate a lot of log messages.
We can manage the lifecycle of our logs using the logrotate utility. By default, it runs daily by cron service. The configuration file can be found on /etc/logrotate.conf. The syslog has a configuration file for itself on /etc/logrotate.d/syslog.
If you don’t want to wait for the next run, you can trigger the execution by running logrotate -f /etc/logrotate.conf.
Using system commands to read the log information
There are a few commands that can save you tons of time when troubleshooting the rsyslog files. We can use tail and head to check the last or top 10 lines, respectively, of a file. We can add -n 6 to define the number of lines.
If you are checking real-time log messages, that can be useful when checking attempts of a logon using a service or httpd messages, for example. We can use tail -f /var/log/file, and that will keep the file live, and any changes will be prompted automatically.
We can use the traditional less to see the entire content of the file and navigate through the pages by typing <space> to go to the next page, and b to go back a page. If you want to search something in the current text, type /string, and the string will be highlighted throughout the text.
The less command does not load the entire content of the file immediately like a regular editor (vi or vim, for example), and that helps when looking with large files, which may be the case when working with /var/log content.
Note: One thing that I don’t like about less command is that when you leave the session, the entire content is gone. If you want to avoid this odd behavior, use -X before the file name and problem solved!
Featured image: TechGenix photo illustration



