When Microsoft first introduced its storage deduplication feature way back in Windows Server 2012, I heard from a lot of people that they weren’t planning on using it. OS level data deduplication was a brand new Windows Server feature, and many were concerned that it might be buggy or that it could somehow cause data loss.
More recently, however, there seems to be a renewed interest in Windows storage deduplication feature. I’m not sure if this is because the feature has had time to mature, or if it is because of explosive data growth, or perhaps because of some combination of factors. At any rate, I wanted to take the opportunity to talk about some important considerations to take into account if you are considering using Windows storage deduplication.
Will deduplication provide any benefit?
Back when deduplication first started to become popular, there was something of a compression ration arms race among vendors. One vendor might advertise that their deduplication product could reduce the data footprint by a ration of 25-to-1. Another vendor might advertise a ration of 50-to-1. In actuality, however, the deduplication ratio that you can achieve depends more heavily on your data than on the actual deduplication. This is true for both Windows native deduplication and for third-party deduplication engines.
Deduplication works by removing redundancy from your data. If there is no redundancy, then there is nothing for a deduplication engine to remove. For example, volumes containing lots of compressed media files (MPEG files, MP3 files, etc.) tend not to benefit from deduplication because these file types are already compressed. The same can also be said for encrypted files and for compressed archives (ZIP files, CAB files, etc.)
With that said, the first thing that I recommend doing is to perform a simple test to find out if deduplication will yield enough of a benefit to make it worth your time. Windows Server includes a tool for this, but before you can use this tool you will need to install the Data Deduplication component.
You install the Data Deduplication component from within Server Manager by expanding the File and Storage Services role and selecting the Data Deduplication component (it is listed within the File and iSCSI Services container), as shown in the figure below.
Once you have installed this component and rebooted your server, you can run Microsoft’s Data Deduplication Savings Evaluation Tool. This handy tool will tell you what you can realistically expect if you move forward with deduplicating your storage. You can execute this tool by going to C:\Windows\System32 and running DDPEval.exe. You will need to specify the drive or path that you wish to evaluate.
For the sake of demonstration, I ran this tool against three separate volumes on my production file server. You can see the results in the screen captures below.

The projected space savings for my M: drive is only 3 percent.

Deduplication could reduce the data footprint on my H: drive by 10 percent
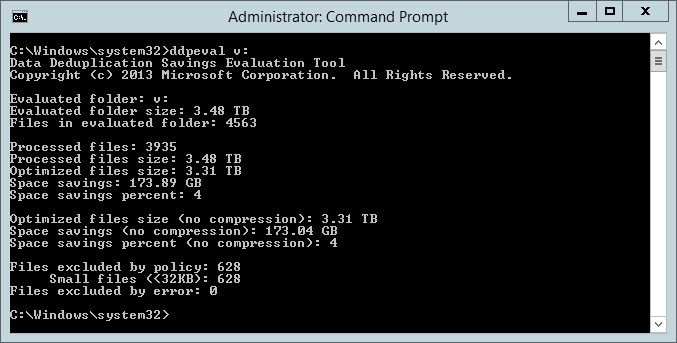
Deduplicating my V: drive would only reduce the storage footprint by 4 percent.
As you can see in the figures above, Windows deduplication engine estimates that it can reduce my storage footprint by anywhere from 3 percent to 10 percent, depending on the volume. In my particular case, this isn’t really enough of a savings for me to justify deduplicating my volumes. Instead, I am simply going to add some more physical storage to my server.
Consider Microsoft’s recommendations
The next thing that I recommend doing is to review Microsoft’s guidelines prior to enabling storage deduplication. Microsoft recommends enabling deduplication for:
- General purpose file servers
- Virtual Desktop Infrastructure (VDI) hosts)
- Virtualized backup applications (such as System Center Data Protection Manager)
This does not mean that these are the only types of volumes that can benefit from deduplication. It simply means that those are the best and most obvious candidates for deduplication.
If you are thinking about deduplicating a volume that contains another type of data then it is important to thoroughly test the process in a lab environment. Some applications (especially those that leverage a database) might not play well with deduplication. Some databases expect to have full control over the storage, and deduplication can theoretically cause corruption in those instances.
You also have to consider the load that deduplication will place on the server. Windows deduplication runs post process, which means that you can run a deduplication job at a time when the server is not under a heavy load. Even so, deduplication is CPU and I/O intensive, so you will need to take that into account.
Windows’ storage deduplication: Final recommendations
Although enabling Windows’ storage deduplication feature is not always the best idea, there are situations in which this feature can be beneficial. If you do decide to move forward with deduplicating one or more storage volumes, then there are two things that I recommend doing.
First, be sure to apply all available Windows Server patched. Some of the Windows Server patches fix deduplication related bugs. This is especially true for KB4025334.
The other thing that I recommend doing is creating a full backup before enabling deduplication. I have never seen Windows’ deduplication feature fail catastrophically, warranting the need for a restoration. Even so, you should never do anything that could needlessly put your production data at risk (such as turning on deduplication without first creating a backup).
One last bit of advice that I would like to pass along is to check to see if your storage hardware supports hardware level deduplication. If it does, then you will likely see better performance by deduplicating your storage at the hardware level than by performing OS level deduplication. Remember, hardware deduplication offloads the deduplication process from the operating system and onto the storage array. This means that deduplication is not consuming CPU cycles on your server. Rather than using these resources to manage the deduplication process, you can dedicate them to running your production workloads instead.




Don’t try this. It will mess up your xls files. They’ll get corrupted.
I haven’t actually seen data corruption first hand, but I have heard a few stories, hence the recommendation to test it before using it in production.
I’ve been using this feature since it was introduced and never experienced a data corruption issue traceable to the deduplication feature.
I’m looking for more information about using Windows’ native dedupe with a SAN that also performs dedupe (such as Pure Storage, etc). I would think it would be better to use one dedupe tech, probably on the SAN side, instead of both concurrently but I’ve not found much information on this.
I would recommend letting your SAN handle the deduplication.
We have ~85 Server on 23 Locations, from 2012 to 2019.
Every Server has dedup activated ( if it is the fileserver for this location )
and we never had any problems with messed files,
AND we have up to 60% savings! No joke.
Everything is ok with this feature and we love it.
Greetings