
Source: Pixabay
Data is an invaluable asset for businesses today. Every company collects large volumes of it from multiple data streams. As a result, data classification is the first step to securing and protecting your data.
While data can give you a competitive edge, it’s also a major responsibility. Data leaks can cause huge losses. Consequently, companies who are careless about their data face hefty fines from regulatory bodies.
In this article, I’ll explain data classification and its importance. I’ll also outline the full process in detail. Let’s begin with a definition!
What Is Data Classification?
Data classification is the process of sorting and labeling data. In essence, it helps businesses understand data collection’s value, sensitivity, and security risks. Teams classify data, so everyone in the company knows:
- What data do they collect?
- Why should the data be protected?
- Who has the authority to access that data?
- What are protection policies best suited to secure the data?
Companies use complex tools to tag every piece of data that enters their system. Let’s dive deeper and see why data classification is important for the digital age.
Why Is Data Classification Important?
Raw data, by itself, is useless. But, companies must process and analyze their data for valuable business intelligence. Data passes through several IT systems, and many employees handle it. So, you must protect your data at every stage. Data classification improves three fundamental aspects of data security:
- Confidentiality—more robust security measures for more sensitive data
- Integrity—adequate IT and storage infrastructure to prevent corruption
- Availability—efficient access controls, so data is trustworthy yet usable
Data classification also helps businesses follow regulatory mandates such as HIPAA and GDPR. Does your company handle private data like customer contact or payment info? If so, you need to be vigilant! So let’s look at some ways you can classify your data.
Data Classification Categories
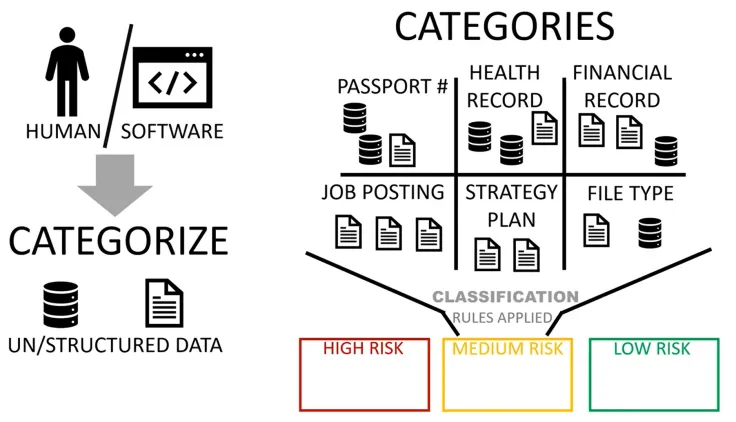
Source: Lightsondata
For data security, all companies sort data into one of 3 categories:
1. Low Sensitivity
Low-sensitivity data is data you can freely distribute and share. It includes public data already available that poses no risk. Examples include:
- Public website content
- Press releases
- Product or service descriptions
- Names and official contact details of managers or customer service reps
- Images of customer-facing service areas
2. Medium Sensitivity
The middle category is for confidential data that requires protection. But, data loss or theft won’t majorly impact the company. This can include:
- Archives of old data
- Details about suppliers and partners
- Some memos and meeting notes
- Policies and procedures
- Marketing content
3. High Sensitivity
High-sensitivity data requires strong protection as data loss will have severe consequences. That is to say, the company may face legal action, loss in share value, or loss of customer trust. Security policies for this data are stringent. As a result, data access is restricted to a select few employees only. Examples include:
- Authorization data
- Private data of customers and employees
- Intellectual properties
- Trade secrets
- Financial data
Here’s an excellent summary of the three main categories of data classification:
| Classification | Low sensitivity | Medium sensitivity | High sensitivity |
| Data label | Public/unrestricted | Internal/sensitive | Confidential/restricted |
| Access | Anyone can access it, including non-employees | The majority of internal employees, contractors, and partners may have access | Select a few authorized employeescan access |
| Security risk | Low | Medium | High |
As you can imagine, mislabeling data has serious effects. But manually assigning every label isn’t practical. Accordingly, most companies use a combination of automation and manual checking for data classification.
How Can You Implement Data Classification?
Implementing data classification is a two-step process. First, leadership prepares a policy and determines labels for different sources. Secondly, data engineers select the right technology to enforce the policy.
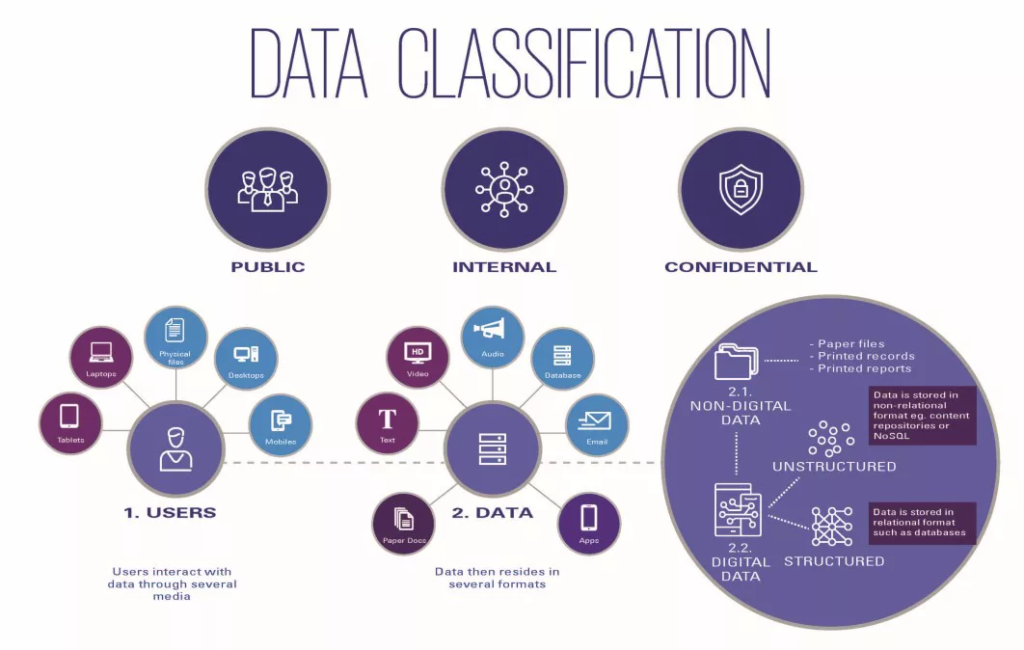
Data Classification Policy
A company’s data classification policy typically includes the following:
- Data types
- Security policies and risks
- Rules for data transmission, retrieval, and storage
It needs to be simple and clear for everyone to interpret.
To start, you need to know the details about your existing data systems. Know your data locations, regulations, and customer expectations around data management. In addition, speak with your stakeholders to outline sensitive categories accurately.
You may find policy-making for your company difficult, but it’s well worth the effort. It provides employees and third parties with a clear framework for data processing.
Data Classification Technology
Your data engineers configure cloud-based services to implement your data classification policy. For example, Amazon Macie is made for AWS. You can also use data management software like 1010data with built-in classification capabilities. In most cases, data engineers use AI to classify data based on:
- Content—specific keywords in the file or document
- Context—file metadata such as file type, file source, or file location
- User—who or what creates the data
Essentially, data classification tools take a safe approach. For example, if a file fits into two categories, it’ll be labeled with the more sensitive option.
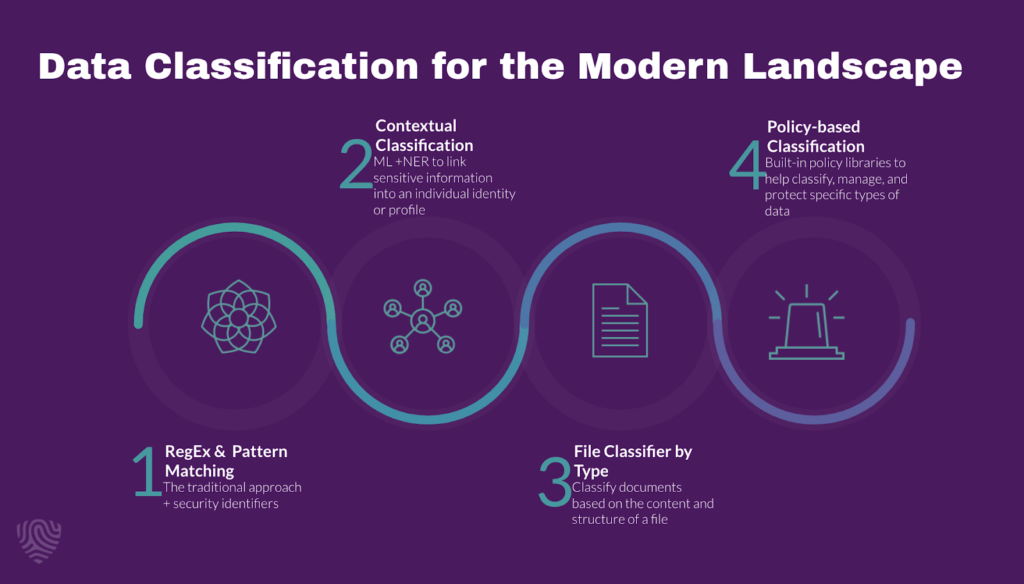
Source: Bigid
Now that you’ve learned about the data classification process, you may be eager to try it out. But are you prepared for the challenges? I’ll go over those next.
Data Classification Challenges
Companies can run into challenges when trying to classify sensitive data. Let’s take a look at some of the most common issues.
Incorrect Classification
Classification technologies may mislabel data due to incomplete info. They may fail to recognize duplicate data or be unaware of certain formats. For example, it may classify all videos as medium sensitivity. Consequently, it may rate the footage of a confidential meeting as medium sensitivity instead of high.
Missing Association
Sometimes, data is considered sensitive because of other associated data. For example, customer names are not sensitive. But when you associate names with medical records, the data becomes sensitive. The classification tools may miss this when sorting data.
Data Volume
Many organizations have large data warehouses and lakes with massive amounts of data. Data volume creates cost and time challenges, especially if sorting legacy data.
Cost Control
It’s difficult to estimate the budget for classification. As a result, costs can spiral as you discover new security policies, access controls, and data sets. The cost of changing a classification can also be high.
These challenges make it difficult to find simple solutions to data protection. But following some best practices can help! I’ll cover those next.
Top 3 Data Classification Best Practices
With so many solutions available for data classification, it’s hard to know how to get started. Nailing down your best practices early is one of the best ways to get ahead on security. Let’s check out my top 3 personal recommendations for getting your data secure.
1. Conduct Risk Assessment before You Start
A data risk assessment helps you identify all security risks you might have. A full assessment will give you greater confidence in your policy. Including security, IT, and legal teams in the process is essential. You can work with them to identify:
- All compliance and regulatory mandates
- Existing company policy requirements
- Confidentiality requirements around existing third-party contracts and customer info
Source: Safetyrisk
2. Catalog Your Data
Most companies have hundreds of data sets. But they don’t all need classification. Instead, you can focus on preparing a data catalog for high-priority data. For example, you may pick customer, financial, and employee data over others. Prioritizing critical data will help you get the most bang for your buck.
3. Plan for Ongoing Maintenance
Generally, the dynamic nature of data means it changes often. Your teams will copy, change, and move your classified data throughout its lifecycle. Having a maintenance plan saves time and effort in re-classification later. Make a process where changes to specific data sets triggers reassessment.
Final Words
Businesses have to collect and manage data responsibly. They’re liable for protecting all the private data they collect. Under those circumstances, data classification is an essential task in data protection. With it, you can sort data based on security risks. Then, you can define policies and access controls to protect high-risk data better. While the process seems straightforward, it’s not so simple. Data volume, duplication, and frequent changes may cause incorrect labeling. Following data classification best practices is essential for success!
Read our FAQ and Resources sections to learn more about data classification.
FAQ
What is GDPR data classification?
Data classification must be done according to GDPR compliance requirements. Companies that store, process, or transfer European Union citizens’ data must follow GDPR laws. For example, they have to restrict access to data related to an individual’s religious and political beliefs.
What is a data classification framework?
A data classification framework is another term for data classification policy. It defines enterprise-wide rules and security requirements for all your organization’s data. These lay out the security levels, labels, and measures for every data type.
What are data classification tools?
These tools are a software technology that classifies data by security risk. They use artificial intelligence technology to process the data. It attempts to understand data context and content before classifying it according to your directions.
What is data classification in machine learning?
Machine learning technology classifies data into different categories for predictive analysis. With it, the problem determines classification categories. For example, consider a machine learning solution that distinguishes cat and dog photos. It classifies any image you input into four categories—”cat,” “dog,” “both,” and “neither.” This type of data classification isn’t related to data classification for security and compliance.
How can I protect sensitive data?
Encryption and secure access controls are the best strategies to protect sensitive data. Only limited employees should have access. Data processing technology should encrypt it if anyone shares or transfers it. If sensitive data is part of a larger context, you should redact it. For example, you can blur names and addresses in otherwise normal documents.
Resources
TechGenix: Newsletters
Subscribe to our newsletters for more quality content.
TechGenix: Article on Data Discovery Benefits
Read more about data discovery and how it can benefit your company.
TechGenix: Guide on Data Center Security
Explore data center security best practices.
TechGenix: Guide on Cloud Data Management
Learn more about cloud data management and the benefits it brings.
TechGenix: Article on Data Protection Best Practices
Read more about data protection and data security best practices.



