If you would like to read the next part in this article series please go to Eseutil – Part 2: Eseutil Switches.
Introduction
There’s a small tool available in Exchange Server 2010 called ESEUTIL. This tool has been around for ages and is primarily known as the tool used for offline defrag. But there’s so much more ESEUTIL can be used for. In this series of articles I will explain a bit more about ESEUTIL. In this part, I’ll talk a bit about Microsoft’s Exchange database technology in general before I focus on the ESEUTIL tool.
Exchange Database Technologies
When you install an Exchange Server 2010 Mailbox Server a Mailbox Database is automatically created. In the following example, a new Mailbox Database is created in the directory “C:\Program Files\Microsoft\Exchange Server\V14\Mailbox\Mailbox Database 0242942819”
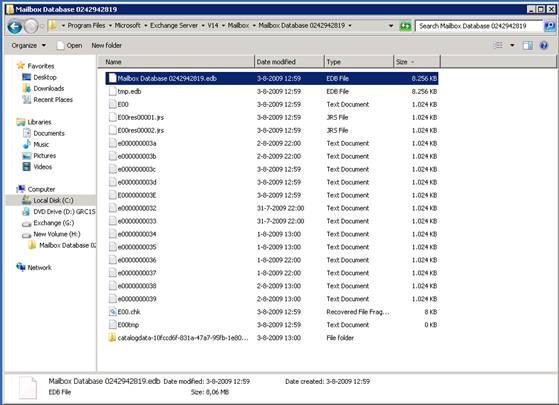
Figure 1
As you can see in this image (Figure 1) a number of files can be seen:
- Mailbox Database 0242942819.edb – this is the actual Mailbox Database file that contains all the messages. The random number “0242942819” is generated during creation of the Mailbox Database and is used to create an unique name within the Exchange Organization
- E00.log – a log file currently in use by the database engine
- E00000003A.log, E00000003B.log, E00000003C.log… – these are log files stored on the disk and can be used for recovery purposes. Please note that a hexadecimal numbering is used
- E00.chk – this is a checkpoint file used for keeping track of the relation between the log files and the mailbox database file
- E00res00001.log and E00res00002.log – these are pre created log files that are used when the disk drive containing the log files is full
- E00tmp.log – a new log file that is currently being created
All log file names in this example start with three characters, E00, which is called the prefix. This prefix will be used for all log files of this particular database. A second database will use a prefix of E01, a third database will use E02 prefix and so on…
The database engine is processing data in so called “pages”, each of which is 32KB in size. This 32KB is the page size in Exchange Server 2010; Exchange Server 2007 uses an 8KB page size while Exchange Server 2003 and earlier use a page size of 4KB. A transaction, which can be a new message, creating a new folder in the inbox, creating a new mailbox or deleting messaging consists of multiple pages. As soon as a transaction is created in memory it is immediately written from memory to the log file in use, which is E00.log in this example. When this E00.log file is filled up with transactions it is saved to the disk using another name, and the name is sequentially numbered following the newest log file. In the picture above it will be E00000003E.log. The number “3E” is called the “lGeneration” number inside the database engine. The database engine will continuously increase this number. Besides the NTFS names the complete set of log files is identified with a “log file signature”; this is automatically generated during creation of the log file and consists of a date and time stamp, followed by a random number. A log file signature can be something like:
“Create time:07/30/2009 09:38:51 Rand:246084591 Computer:”
Note:
There’s no value after the last column in the log file signature.
The mailbox database also has a signature, but now called a database signature. This can be something like:
“Create time:05/12/200908:33:12 Rand:812305 Computer:”
Again, there’s no value behind the last colon. In the remainder of this article I will not write down the “Computer:” part of the signatures because of simplicity. The pages are not written immediately to the database file but only after some time. They will stay in memory just in case Exchange needs the page again. This way a valuable disk I/O is saved since it is still in memory. The more memory inside the Exchange Server, the more information can be kept in memory. When the page is saved into the database file, the checkpoint file is updated. The checkpoint file keeps track which pages are written into the database. Pages “under” the checkpoint file are written into the database file, pages “above” the checkpoint file are still in memory and not yet written into the database file.
So, where’s the actual data? It’s in the server’s memory, it’s inside the log files or it is inside the mailbox database.
In short:
- Mail data is initially processed in memory, separated into pages.
- Updated pages, forming a transaction, are written to the log file.
- If pages are no longer needed by Exchange these pages are written to the database.
- The checkpoint file is updated to reflect the new location of the checkpoint.
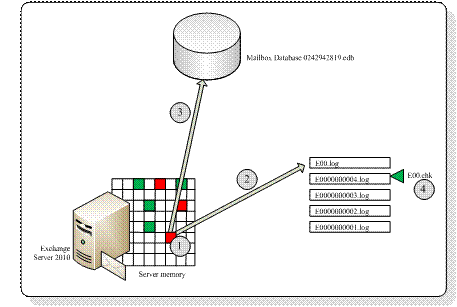
Figure 2
It is recommended to move the Mailbox Database and the accompanying log files and checkpoint files to another, separate disk. This can be a local physical disk, but of course it can be LUN located on a SAN or on an iSCSI device.
The Mailbox Database file is actually an open file, where the missing data is inside the log files. This is the case when the Mailbox Database is mounted and Exchange is processing data. When the Database is dismounted, all information inside the memory is flushed to the Database, the checkpoint file is updated (all information is now inside the database, so it’s at the last position) and the database is closed. The database now is in a “consistent state”. This is also sometimes referred to as a “clean shutdown”.
Now suppose the server crashes, or less catastrophic, we pull the power cable from the server. The database isn’t in a consistent state since it wasn’t shutdown properly, so it is inconsistent, also referred to as a “dirty shutdown”. But all data is still in the log files, so Exchange is able to reconstruct the last part of the database based on the information found in the log files. This process called automatic recovery takes place when the server is started and the database is mounted again. Exchange knows that all information before the checkpoint is already in the database, so Exchange will start at the point of the checkpoint for its recovery and only replays that information. In 99% of all cases the database are normally mounted in such a scenario, but for the remaining 1%, the ESEUTIL tool can be very useful. Also bad things can happen with the database pages on the physical hard disk, or in the disk controller. Then pages get corrupted and usually result in a -1018 error in the event log. ESEUTIL can help you in this case as well. But there’s also a warning: since ESEUTIL is a very powerful tool it can also destroy your database which will result in a loss of data. So make absolutely sure that you have a decent backup of your Exchange databases, or play around with ESEUTIL on a different, isolated server to prevent any ‘mistakes’.
ESEUTIL
ESEUTIL is an Exchange database utility located in the \bin directory of Exchange server. A number of switches are possible with ESEUTIL:
- ESEUTIL /D – Used for offline defragmentation of a Database
- ESEUTIL /R – Used for recovery purposes of a Database
- ESEUTIL /g – Performs an integrity check of a Database
- ESEUTIL /k – Performs a checksum test of a Database
- ESEUTIL /p – Repairs a Database when it’s corrupt (and beyond recovery)
- ESEUTIL /m – can dump header information of a Database and Log Files
- ESEUTIL /y – can copy large files like Mailbox Database files efficiently
- ESEUTIL /c – Is used to ‘hard recover’ a database during an online backup
I’ll start with the informative options first, the options that are not destructive.
Header Information
Every Database file, log file and checkpoint file have a header. This header contains (internal) information used by Exchange. It is possible to read the header information with ESEUTIL /m. To read header information from a database file you can use the following command:
“ESEUTIL /MH “Mailbox Database 0872095299.edb”
Please note that the database needs to be offline to read the header information! In the database header you can find all information regarding this particular database; like the date it was created (in the database signature), if it was switched off properly (dirty shutdown versus clean shutdown), the accompanying log file signature and for example when the last full and incremental backup was created (unfortunately not visible in the screenshot).

Figure 3
In this screenshot (Figure 3) you can see clearly the Database Signature (Create time: 03/31/2010 18:20:50 Rand:82186442) and the accompanying Log File Signature (Create time:10/16/2009 12:12:19 Rand 3690040). To check the header of the log file you can use the following command:
ESEUTIL /ML E00.log
In this header information you can see when the actual log file was created, its lGeneration number (the sequential number this log file will be renamed to), the log file signature and the accompanying database information. If this log file and the database file belong together you will see the same log file signature information in both files.

Figure 4
In this screenshot (Figure 4) you can see clearly the Log File Signature (Create time:10/16/2009 12:12:19 Rand 3690040). This does match the Log File Signature we’ve seen in the header information of the Database File, so this Log File “belongs” to the previous Database. To check a sequence of log files belong to each other you can enter the following command:
ESEUTIL /ML E00
This command will read all log files and show immediately if they are in the same sequence, if the sequence is complete and if all log files are ok. If a log file is corrupt it will be shown here. To check the header information of the checkpoint file you can use the following command:
ESEUTIL /MK E00.chk
Like the previous options, you will find information when this checkpoint file was created and you’ll find information regarding the accompanying database file and log files. And again, the database signature and the log file signature will be used for this match.

Figure 5
In the header information you can see the Log File Signature: Create time: 10/16/2009 12:12:19 Rand 3690040. As we have seen in the header of the Log File E00.log this is the same Log File Signature, so this Checkpoint File belongs to the E00.log Log File.
Therefore, if you want to check if all three files belong to each other you have a puzzle in your hands waiting to be solved by writing down all header information from these three files.
The last option is to check used space within a Mailbox Database. You can retrieve all information regarding the internal usage; like the amount of internal tables (used to construct the database internally), their names, what kind of tables etc. But the first entry is interesting because it shows the available “white space” inside a database. This is the amount of free space that can be reclaimed from the Database file (i.e. the famous Offline Defragmentation). I will get back to the reclaiming free space in the next article.
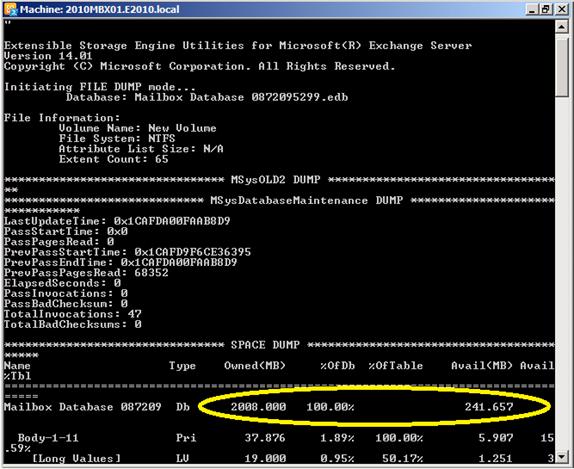
Figure 6
So, the Mailbox Database as shown in the picture has 241MB of free space available, on a total size of 2008 GB.
Conclusion
In this article I tried to explain the internal processing of data inside an Exchange Server and how the Mailbox Database, the Log Files and the Checkpoint File are tied together.
You can use the ESEUTIL tool to retrieve all kinds of interesting data from these files with the /MH, /ML, /MK and /MS option. In the next article I will focus on the other switches that can be used with the ESEUTIL utility.
If you would like to read the next part in this article series please go to Eseutil – Part 2: Eseutil Switches.



