In 2000, Google chief executive Larry Page remarked how he’d want to divide the few terabits of the whole Internet data into hard drives scattered across the globe, and put it all on memory to speed up operations. This discussion happened in an Intel Developer Forum, and did not really gather much buzz.
More than 17 years later, the web is incomparable to what it was back then, in terms of its reach and expanse. However, the core idea remains as valid and feasible as ever. On a more realizable level, it’s surfaced in the form of in-memory computing.
Cloud computing giants, enterprises, and financial institutions, among others, are recognizing and moving toward keeping their data “in memory.” In 2013, Gartner highlighted in-memory computing as a strategic initiative for IT and data-driven organizations. Now if they could just invent a glazed donut that did not have the calories an actual glazed donut has. Then you could eat 10 donuts without putting on 10 pounds!
In-memory computing and the enterprise
Midsize to large companies need to make the most of their data. Driving data analyses-linked efficiencies demands cost effective, speedy, and flexible management of data.
In-memory computing delivers precisely this, and more, centered on the power to make sense of millions of numbers within fractions of a second. In-memory computing can deliver data-crunching benefits across applications and do it in real time. Enterprises have multiple reasons to desire this:
- Understand customer demands and their unstated expectations.
- Adjust pricing on the move to drive sales.
- Proactively identify production line problems and eliminate them.
- Conduct real-time financial modeling to drive critical financial decisions.
- Create agile and responsive supply chains.
In-memory technologies
Conventional Big Data and analytics tools are limited by the inherent speed limitations of storage systems. When these calculations are done in near real-time (instead of 20-30 seconds for complex calculations — no, deciding whether you want a corn dog or some fried chicken for dinner does not fit well into this example), the adoption of Big Data improves exponentially, and helps businesses realize the business potential of technologies they’ve already invested heavily in.
Let’s understand how in-memory computing helps enterprises overcome their Big Data woes.
Move from disk to RAM
Conventionally, organizations store data on spinning physical disks that can be electronic, optical, magnetic, or any other media. These technologies are suited well for homogeneous data structures. However, in-memory databases use random access memory (RAM) for data storage, which results in faster response times and processing.
In lab tests, SAP’s HANA database (an in-memory database) was able to process 1,000 times more data in almost half the time as compared to traditional databases. That’s the kind of improvement in-memory computing and databases bring.
Handle unstructured data

The modern enterprise generates structured, semi-structured, and unstructured data. Ideally, they want a database that helps them manage all three forms of data without impeding the speed of access and operations. In-memory computing works well with unstructured data such as social media news feeds, computer generated logs, emails, etc.
This capability enhances the organization’s readiness to get a broader data-driven view of business operations, and no, this does not mean the business can order you some pizza faster! Well, perhaps it does! Do you want some bell peppers on that?
Row architecture to column architecture
In-memory computing stores data in columnar architecture, called online analytical processing (OLAP). This is in contrast to the conventional OLTP relational database-styled organization of data in rows. OLAP facilitates compression of data, advanced analytics, and fast manipulation of significantly large sets of data.
ERP and in-memory integration
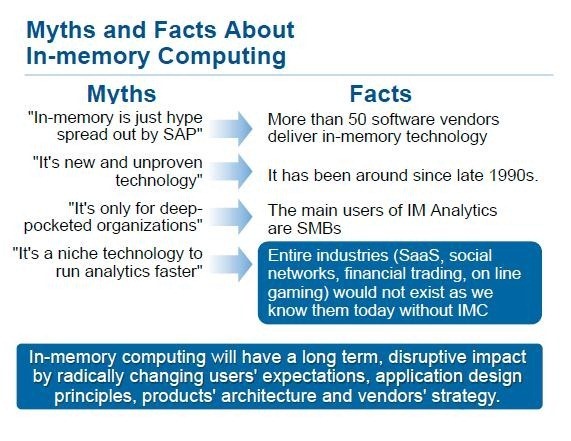
The enterprise resource planning (ERP) market is in the middle of a remarkable transformation based on in-memory computing and in-memory databases. Oracle announced the launch of 13 in-memory applications, reporting performance improvements of almost 20 times. Also, SAP, the market leader in enterprise ERP, shifted core applications to in-memory database, and reported hundreds of customer endorsements after they did this.
More notably, SAP’s HANA has recently been certified to run on Microsoft Azure, which means that it could be the first fully cloud-hosted enterprise analytics solution. With ERPs that can manage data more than 10 times faster than they did earlier, business can immediately start reaping the benefits of their data warehousing and Big Data practices.
The in-memory computing wave has witnessed significant interest from vendors as well, with Microsoft and IBM joining the ERP big shots in developing technologies like in-memory DB2 and SQL. Then, we have open-source platforms like Hazelcast, VMWare’s SQLFire, Software AG’s BigMemory, and several upcoming tools and platforms that can change the way organizations drive benefits out of the years of data they’ve stored on their servers.
The business case for the future
In-memory computing has the power and potential to change the way datacenters are managed. Presently, it’s a fact that most datacenters sit around idle most of the time. Well, they do this very quietly! They do not seem to complain much!
Microsoft has admitted that its datacenters are working only 15 percent of the time. Wow! How do I sign up for that job? The real estate, power consumption, hardware, and workforce productivity overheads are huge. In-memory computing can help put datacenters to greater use.
- By redesigning around memory-based storage, a conventional datacenter would be able to store up to 40 times the data it can store now.
- The number of racks required to achieve capacities of 1 million input/output operations per second (IOPS) will be reduced to one-fourth.
- Energy consumptions of datacenters could be reduced by 80 percent, because memory-based systems require less air conditioning and consume less energy.
- In-memory computing-based storage systems will be able to hold up to a few petabytes of data, transforming the power of Big Data and analytics.
Driven by in-memory computing, Big Data and analytics will be able to deliver analyses results and predictions in near real time. This will make IoT more manageable, when millions of sensors and devices enter the Internet ecosystem and generate many times more data than we ever imagined.
For enterprises that treat their data as their digital gold, in-memory computing is the vehicle that will help them drive past laggard competitors. If you are going to slow you are just in the way. See ya!
Enterprise decision makers such as IT directors, data officers, and CIOs need to push vendors for affordable in-memory solutions, drive focused analytics efforts toward achieving critical business goals, and pay attention to high potential capabilities to enable phased adoption of these technologies.




You should look into what Symbolic IO is doing and maybe write a post about them. Seems like they found a way to take advantage of in-memory computing with not just the use of software but with the efficient combination of hardware components.