One of the most popular features that appears from time to time in our long-running WServerNews newsletter (now in its 23rd year!) is a section called Ask Our Readers. Individuals who have subscribed to our newsletter (currently almost 200,000 IT pros from all over the world!) sometimes send us questions about troubleshooting some technology issue they’re struggling with or to ask for our recommendation concerning some product or service they’re looking to use or acquire. (By the way, you can subscribe here if you’re not already part of our growing WServerNews community.)
Whenever we receive such questions, we insert an “Ask Our Readers” item into our next issue where we share the subscriber’s question and ask if any of our readers (many of whom are experts in their particular IT field) can help the questioner by suggesting a possible solution or workaround. Sometimes we get only a couple of responses to the question, and often at least one of these is helpful to the questioner. Occasionally, if it’s a particularly difficult or complex question, no responses may be forthcoming from our readers, and in that case, we may try to redirect the questioner to some other online resource or forum where they may find more help concerning the matter. And once in a while, a subscriber’s question may spawn off a whole series of replies leading to a lengthy technical discussion that may raise additional questions that we then put forth to our readers asking for their help concerning them.
Recently, however, I experienced a technical issue of my own that has left me somewhat stymied. But instead of using our WServerNews newsletter to seek help from the larger IT pro community, I thought that this time I’d try something different and write up an article about it for our TechGenix website.
The background
The problem I encountered happened on one of the Windows 10 PCs in our office. The PC is an HP EliteDesk 800 G1 Tower PC bought refurbished from Newegg a couple of years ago. The machine has a 512GB KingFast solid-state drive (SSD) disk in it. It’s always a good idea anytime you ask for help with an IT problem to start by providing the hearer with basic background info like this, otherwise, instead of answers, you just end up getting more questions from those listening to your woes. Everything was going swimmingly well on this machine until a notification appeared indicating that updates had been downloaded and were ready to be installed, and the machine only needed to be restarted to complete the installation of the updates. (Windows 10 on this machine is set up to download updates but not install them until told to do so.)
Troubleshooting the issue
So, I clicked the restart notification and selected the option to restart the machine immediately. My desktop disappeared, and an “installing updates” message was displayed, indicating progress on installing the updates. But then suddenly, a BugCheck screen (used to affectionally be known as the Blue Screen of Death or BSOD) appeared indicating that a 0x0000001E KMODE_EXCEPTION_NOT_HANDLED Stop error had occurred. What this Stop error apparently indicates is that a kernel-mode program generated an exception that the error handler didn’t catch. The first of the four parameters displayed in the Stop error was 0xC0000005, and this interprets as STATUS_ACCESS_VIOLATION, which means a memory access violation occurred. The fourth parameter 0xFFFF820D8A96FC60, which indicates the address in memory that the driver was attempting to access. Anyway, that’s according to Microsoft Docs, at least. Big help.
The investigation
Did I just install a flaky update? As I mentioned in a recent issue of our WServerNews newsletter, Microsoft has been notorious of late for releasing software updates with bugs in them. So my first guess was that this was what had occurred, but before I tried the standard troubleshooting procedure when Stop errors are encountered, I decided to just start by manually powering the machine off and powering it on again.
And guess what? The machine booted up, the installation of updates completed, the login screen appeared, and I logged on and got my desktop. And when I opened some of my applications, everything seemed fine. Hmmm.
Better check the event logs and see if I can find out more about what happened is what I thought of next. So, I opened up Event Viewer as administrator and created a custom view to display all critical and error events that had recently been logged in the Windows logs:
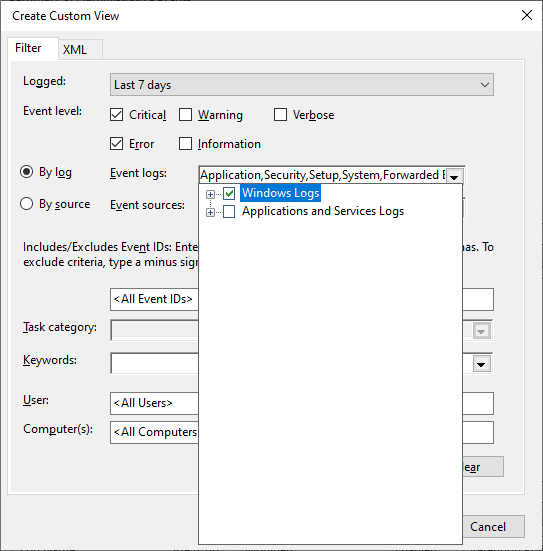
I quickly found the BugCheck error that had been logged some minutes ago:
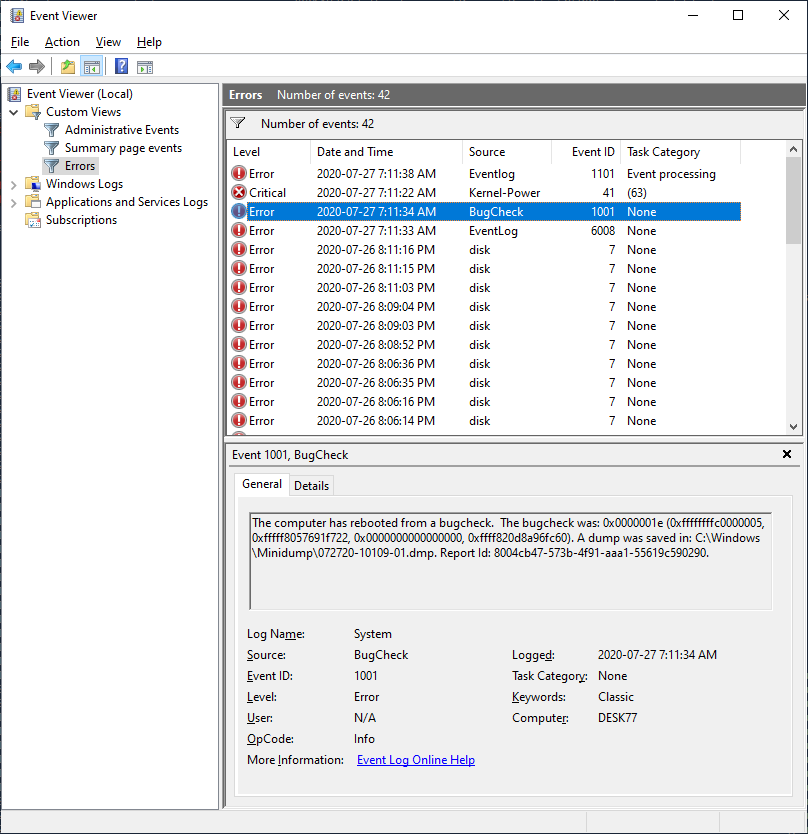
Not much help there, so I clicked the More Information link to get some event log online help on the matter. My browser opened and displayed Page Not Found. Great.
Then I noticed the bunch of disk errors that had been logged in the above picture. I clicked on one of these disk errors to select it and view more information:

Eeeshhh, a bad block on my SSD disk, which is my system disk. Let’s check some more of these disk errors. Bad block, bad block, bad block. Not so good.
When I came to the end of the dozen or so disk errors, Event Viewer displayed a bunch of WindowsUpdateClient errors that had been logged just prior to the disk error events:
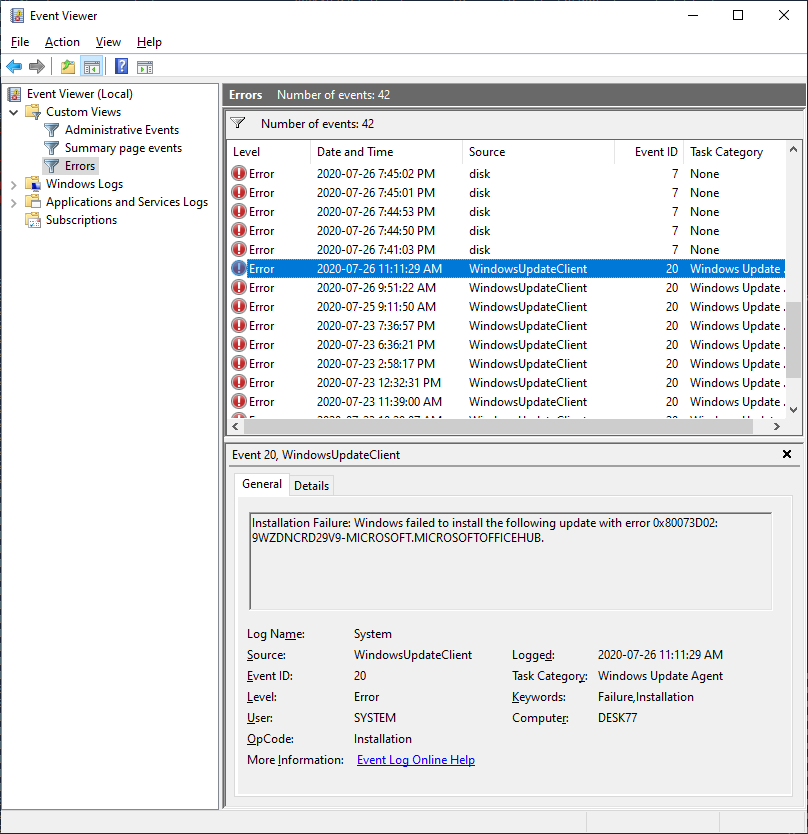
As expected, these WindowsUpdateClient error events indicated that installation failed for the various pending updates on the system. But the updates all did get installed successfully after I powered the machine off and on again.
So, did one of the updates cause problems with some sectors on my disk? Or, more likely, did some bad blocks suddenly appear on my SSD and end up borking the update process? But why did the updates get installed successfully after I powered the machine off and on again? How did Windows handle the bad blocks that had suddenly caused a kernel mode exception?
Time to run chkdsk. Let’s go the full nine yards and try to repair anything that needs fixing on the disk and recover any readable information from any bad blocks it can find on the drive. Here’s the command I ran in an admin CDM prompt window:
chkdsk c: /f /r
I then restarted Windows to start chkdsk running on the system drive. Yep, chkdsk seems to be running OK, so time for coffee.
(later)
The logon screen has appeared, so let’s log on and start Event Viewer again so we can see what chkdsk has reported. To do this, we’ll create another custom view like this:
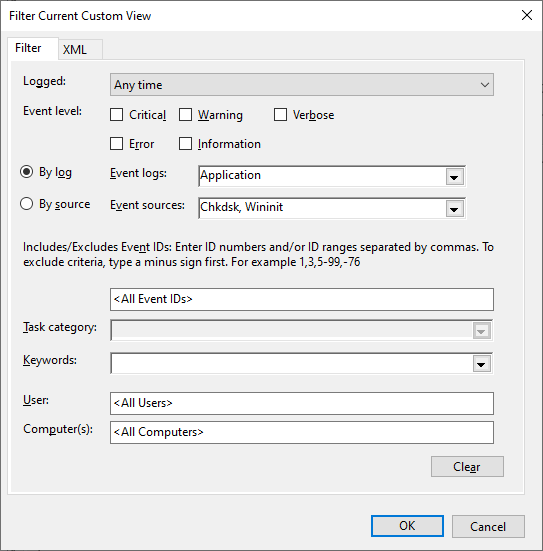
Let’s take a look at that chkdsk event to see what chkdsk has reported:
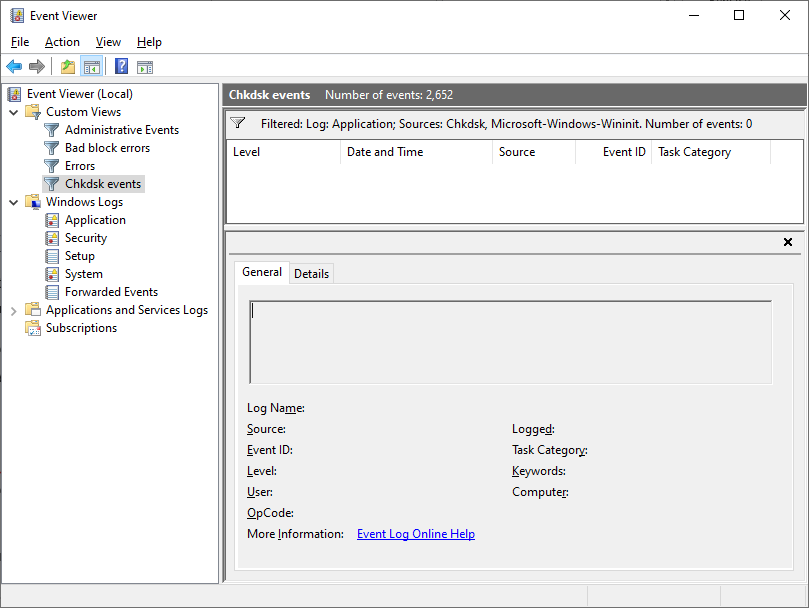
What? No event was logged by chkdsk? How can that be? I checked my monitor a couple of times during my coffee break, and chkdsk was merrily chugging along through each of its five stages of operation. What’s going on?
Outstanding questions
So, should I be worried about the future health of the SSD disk in this system? No additional bad block errors have been logged in Event Viewer since then, but this does this mean I’m safe. How can I test the health of my SSD drive? What software tools would readers recommend for this purpose? I ask this because this is actually the first time I’ve ever encountered bad blocks appearing on an SSD in one of our office machines. Perhaps I’ve just been lucky. What would our readers recommend at this point for investigating the problem further and staying more on top of things in the future with regard to the health of our SSD drives in our systems? And why didn’t chkdsk log any results in Event Viewer when I ran it on my system.
I’m open to suggestions concerning all this, so please feel free to use the comments feature below to share your thoughts and expertise on these matters. And hopefully, your troubleshooting responses will help make this article useful to anyone else who encounters problems of this sort, which is really the ultimate reason that I’ve written this article.
So, thanks in advance!
Cheers,
Mitch Tulloch
Senior Editor for WServerNews
P.S.: Did I already mention that you should subscribe to our newsletter? 🙂
Featured image: Shutterstock




Hi Mitch,
I think you should look if your disk included a software that can check verify the disk.
I’ve bought a year ago a Samsung SSD disk and it was delivered with a software called Magician that among other things could verify the disk.
Best regards
Yes I tried that. I reached out to KingFast the Chinese company that makes the SSD in my Lenovo system to ask whether they had any tools available for checking their SSDs as none was included with my Lenovo system. But I haven’t received any reply from them yet.
When I have encountered errors like that in the past (non-SSD) it was usually an indicator of imminent complete drive failure.
That’s encouraging, guess I better do another full Veeam system backup and buy a replacement SSD!
I am certainly not a storage expert. From my years of reading about SSD’s they have evolved, I have gotten the impression that SSD’s are not managed very well by chkdsk because that tool is expecting to simply mark the file table with bad sectors so data is not written there again. However, SATA wear leveling most likely does not honor the file table the way chkdsk expects. The SSD controller handles so much that I think of it much like storage virtualization where the OS and most tools lack direct access to the memory. KingFast does list the controllers they use based on the model and capacity of the drive. For example, I see they use PHISON S2 controllers on some of their drives and SMI2258XT/S11 on many of their drives. Looking at various reviews, the SMI, or Silicon Motion, controller is pretty middling products that get the job done while being very inexpensive. Silicon Motion does not seem to have any software available to correct errors. Theoretically, their Error Correcting Code should have been preventing the errors in the first place. The Phison controllers are similar and also do not appear to have software like Samsung provides.
What still bugs me Mark is why after I ran chkdsk there was no event logged for it in the Event Viewer logs with details of what chkdsk found (or didn’t find).
I’ve never really been convinced that it works (especially on SSD devices) but you might run SpinRite from Gibson Research on level 2. Fans rave about it but I have never been able to rescue a drive using it (in a couple of cases chkdsk has saved me and many in the IT community disparage chkdsk efficacy).
Thanks Fred but I’ll probably pass on that. Since the PC is running fine the bad sectors must have self-repaired somehow )i.e. the bugcheck error never repeated itself) so running SpinRite in Level 2 mode which does reads only but also attempts to perform active recovery if any bad sectors are found seems unnecessary at this point. But thanks anyways 🙂
Over-provisioning and relocation probably saved you. When the drive noticed the bad sectors, it relocated the data and marked the original sectors as unusable.
If you can, find a S.M.A.R.T app that can read your drive and check whatever their version of “Relocated Sector Count” is.
Yes when I run Hard Disk Sentinel it displays a count of 8 reallocated sectors which is the same as the number of bad sectors reported in the Event logs. Since Windows rebooted successfully after the bugcheck I assume the bad sectors were detected during writes not reads which allowed the SSD controller to remap the bad sectors. But I’ll keep an eye on the Relocated Sector Count and see whether it increases further, thanks.
– You have an SSD, so you would only run chkdsk c: /f, not chkdsk c: /f /r (you do not check the free space on an SSD as that is handled by the SSD firmware).
– If the system has to reboot due to the volume running the current operating system, see results in Event Viewer (run eventvwr): Windows Logs: Applications: (source =) Wininit
– Lastly, if this is a mission critical workstation you have no choice but to run a stable, tested OS such as Debian. Running mswin is not advised.
Thanks Superman but my point is that chkdsk *was* running on my machine, then I took a break, then when I came back it had finished and the machine had rebooted. So I logged in and filtered event logs for both chkdsk and wininit events and there were none for the chkdsk operation that had just been run on the machine. Why not? I don’t know.
As for replacing Windows with Debian, see my recent article https://techgenix.com/windows-expert-to-learn-linux/ and feel free to comment 🙂
I’m in the same boat, currently. System crashed hard, but got back up and running. StorageCraft ShadowProtect 5 backup software says automatic backups will not run until chkdsk is ran. So I ran chkdsk. Same issue. Ran chkdsk again, this time going right to the machine when it was done to check Event Viewer. No logs.
I doubt your issue is due to using an SSD, as the machine I’m having issues on just has a standard 7.2K RPM SATA hard drive. Chkdsk seemed to run suspiciously fast, though.
I don’t have an recommendations, that’s actually how I ended up here. I was searching around. Just wanted to chime in and let you know that I’m having the issue on a non-SSD machine. Hopefully we can find some kind of solution. I’m ready to pull the drive and manually rebuild the machine on a new one. The machine hasn’t backed up for some time, and that’s making me nervous.