If you would like to read the other parts in this article series please go to:
- OSI Reference Model: Layer 1 Hardware
- OSI Reference Model: Layer 2 Hardware
- OSI Reference Model: Layer 3 Hardware
- OSI Reference Model: Layer 4 Hardware
- OSI Reference Model: Layer 5 Hardware
If you would like to be notified when Russell Hitchcock releases the next article in this series please sign up to the WindowsNetworking.com Real time article update newsletter.
In my last five articles I have written about the lower five layers of the Open Systems Interconnect (OSI) Reference Model. In this article I will discuss the sixth. Layer 6, the Presentation Layer, is the first layer concerned with transmitting data across a network at a more abstract level than just ones and zeros; for instance when transmitting letters, how are they represented as ones and zeros (or rather, how are they ‘presented’ to the lower layers of the OSI Reference Model).
This functionality is referred to as translation, and allows different applications (often on different computing hardware) to communicate using commonly known standards of translation, called transfer syntax. Besides transfer syntaxes which can represent strings as ones and zeros, there are others which can transfer more complex data, like objects in Object Oriented Programming languages. Extensible Markup Language (XML) is an example of this.
COMPRESSION
Another important function of the presentation layer is compression. Compression is often used to maximize the use of bandwidth across a network, or to optimize disk space when saving data.
LOSSLESS COMPRESSION
There are two general types of compression Lossless and lossy. Lossless compression, as its name suggests, will compress data in such a way that when decompressed the data will be exactly the same as before it was compressed; there is no loss of data. Lossless data compression will typically not compress a file as much as lossy compression techniques, and may take more processing power to accomplish the compression; these are the trade-offs one must consider when choosing a compression technique.
DICTIONARY ENCODING
One common way to implement lossless data compression is to use a dictionary. This method, often called a substitution coder, will search for matches between the message to be sent and messages in the dictionary. For example, you could use a complete English dictionary as the dictionary and when you wanted to compress the contents of a book you would simply replace each word by that word’s location in the dictionary. Decompressing this compressed message works in the opposite way, the locations are replaced by the word in that location.
Substitution coders can also be much more complex than the example above. For instance, the LZ77 and LZ78 algorithms work with a dictionary referred to as a sliding window. A sliding window dictionary is a dictionary which changes throughout the compression process. Basically, a sliding window dictionary contains every sub-string seen in the last N bytes of data already compressed. When using a sliding window dictionary, the compressed data will require two values to identify the string instead of just one. The two values are the location of the start of the sub-string, which states that the sub-string is found in the sliding window starting X number of bytes before the current location, and the length of the sub-string.
RUN-LENGTH ENCODING
Another basic example of lossless compression is Run-length Encoding. A Run-length encoding algorithm will replace a subset of data which is repeated many times, with the data subset and a number representing the number of repetitions. A real-life example where run-length encoding is quite effective is the fax machine. Most faxes are white sheets with the occasional black text. So, a run-length encoding scheme can take each line and transmit a code for white then the number of pixels, then the code for black and the number of pixels, and so on. Because most of the fax is white the length of the transmitted message will be greatly reduced.
One must use this method of compression carefully. If there is not a lot of repetition in the data then it is possible that the run-length encoding scheme would actually increase the size of a file.
LOSSY COMPRESSION
Of course it is not always feasible or desirable to use a lossless compression technique. In many instances lossless compression methods will simply not compress the data enough to be useful. In other instances, the lossless compression techniques will take too much processing power to compress and/or decompress, and in many situations lossy compression methods can give results virtually indistinguishable by humans. Figure 1 shows a graph of relative compression speeds.
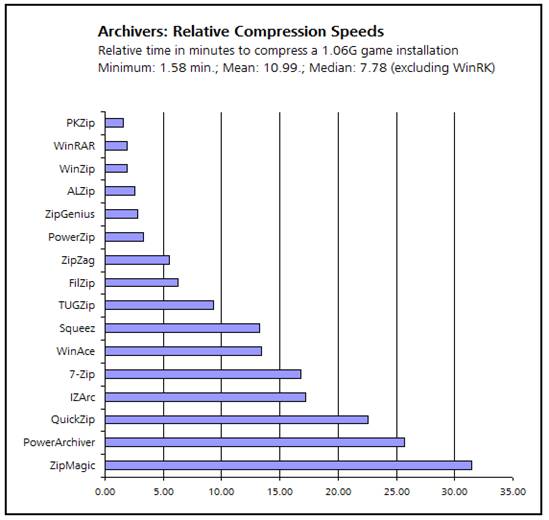
Figure 1: Graph of compression speeds (Source: www.donationcoder.com)
DIGITAL IMAGE COMPRESSION
Compressing digital images is a situation where one should be careful when choosing whether to use a lossless or lossy compression method. Often the choice is dependent upon the image being compressed. Images, like medical images, where fine details are critically important will most likely require lossless compression. While photos of your family vacation could probably benefit from the reduced file sizes provided by lossy compression methods.
In the case of your family vacation photos, choosing a lossy compression method does not mean you will end up with poor quality photos. In fact many lossy compression methods for digital images can take advantage of the fact that the human eye is more sensitive to brightness than to slight changes in color. This means that the compression method will save very similar colors as the same color while saving the brightness data in a lossless fashion. This is called chroma sub-sampling.
DIGITAL AUDIO COMPRESSION
Another example where lossy compression methods may be a good choice is with digital audio compression. Lossy digital audio compression techniques take advantage of a field of study known as psychoacoustics. Basically, psychoacoustics is the study of how humans hear and perceive sound.
One aspect of psychoacoustics relevant to digital audio compression is the fact that humans can only hear sounds at a frequency between 20Hz and 20kHz. Many lossy digital audio compression techniques take advantage of this and do not save any information related to frequencies outside of this range.
Also related to the frequency range which humans can hear, is the fact that sounds must be louder to be heard at all at higher frequencies. This means that lossy compression techniques can sample sounds of low intensity at these frequencies much less rigorously, or not at all. This also means that designers of these compression techniques can ‘hide’ any noise artifacts (as a result of the compression) in these high frequencies where they will not be perceived.
Another aspect of psychoacoustics which is used extensively in lossy digital audio compression is a phenomenon called masking. This is where a loud sound causes a quieter sound which occurs at the same time to be inaudible. This, of course, is frequency dependent but nevertheless this is a phenomenon widely exploited by engineers in the audio compression field. Basically, when there is a loud sound on an audio track the compressed file will not save data related to other sounds at the instant. The result, if done carefully, is that the human ear will perceive all sounds the same as in the uncompressed track.
One area where lossless digital audio compression is gaining popularity is with digital archiving. Audio engineers and consumers who want to save an exact copy of their audio files are increasingly turning to lossless digital audio compression. One reason for this is that the cost of digital storage is dropping and people can afford to use storage space for this reason.
Despite the low cost of digital storage, lossy digital audio compression is still king when it comes to portable storage of music. For example, your iPod will use lossy digital audio compression because when you want to carry the storage around with you, there is only so much data you can store; using lossy compression will allow you to carry more songs with you. Another area where lossy compression is king is in audio streaming. Even though the cost of bandwidth has decreased significantly in recent years, there is still the need to reduce the bandwidth used by many applications. So, everything from online radio to VoIP applications tend to use lossy compression techniques.
If you would like to read the other parts in this article series please go to:
- OSI Reference Model: Layer 1 Hardware
- OSI Reference Model: Layer 2 Hardware
- OSI Reference Model: Layer 3 Hardware
- OSI Reference Model: Layer 4 Hardware
- OSI Reference Model: Layer 5 Hardware
If you would like to be notified when Russell Hitchcock releases the next article in this series please sign up to the WindowsNetworking.com Real time article update newsletter.