If you would like to read the other parts of this article series please go to:
- Deploying Exchange 2007 Multi-site CCR Clusters – Do’s and Don’ts (part 1)
- Deploying Exchange 2007 Multi-site CCR Clusters – Do’s and Don’ts (part 2)
- Deploying Exchange 2007 Multi-site CCR Clusters – Do’s and Don’ts (part 3)
Introduction
In part 3 of this four part article series, we took a look at transport dumpster strategies as well as placement and configuration of the file share witness.
In this, part 4, we will continue where we left off in part 3. We will take a look at fail-over between the cluster nodes and how a fail over between nodes located in separate datacenters affects the end-users. Finally we will talk a bit about backup strategies when deploying a multi-site CCR cluster.
This is the last article in this multi part article.
Failover behavior between Cluster Nodes
If two votes are available, a failover of the CMS to the passive node in the backup datacenter will occur automatically. This means that, unlike SCR, no manual intervention is required. At first this sounds like an excellent idea as that is one step less to perform during a site failover. But, are you really sure you want to have the CMS fail over to the backup datacenter just like that? This question really depends on things such as number of users, bandwidth between the datacenters, and number of storage groups/mailbox databases. Imagine that a minor unplanned network outage happens in the primary datacenter and triggers a failover of the CMS to the backup datacenter. In a worst case scenario, a failover of the CMS can take up to 30 minutes in some environments. On top of that you suddenly have a situation where all Exchange HT and CAS servers, Domain controllers/Global Catalog servers as well as Outlook clients must communicate with the CMS now in the backup datacenter. If you do not want an automatic failover of the CMS to occur during a situation where the IP address or the network name of the cluster is unavailable, consider pausing the cluster service on the passive node.
Note:
The reason why you should pause and not stop the cluster service on the passive node is because when you pause a node, existing groups and resources will stay online while additional groups and resources cannot be brought online on the node. Because of this, the cluster service will not stop log file shipping from occurring between the cluster nodes. However, stopping the cluster service on the passive node would make the cluster stop functioning and break log file shipping until the Cluster service is restarted.
To pause the cluster service on a cluster node in a Windows Server 2008 failover cluster, open the failover cluster management console > expand the cluster and then Nodes. Now right-click on the passive node and choose Pause in the context menu as shown in Figure 1 below.

Figure 1: Pausing the Cluster service on the passive CCR cluster node
You can also pause the cluster using cluster.exe if you like. To do so use the following command:
CLUSTER.EXE <name of WFC> NODE <name of node> /PAUSE

Figure 2: Passive Cluster Node Paused
When a disaster hits the primary datacenter bringing the active node down, you would then need to failover to the cluster manually by first resuming the passive node as shown in Figure 3. This is even though you have a third vote in the form of a file share witness available in the primary datacenter or a third datacenter.

Figure 3: CMS is currently offline
In addition, if the cluster core services were not owned by the passive cluster node in the backup datacenter, when we paused the cluster on that node, you must force the cluster core resources online before unpausing the cluster node after the loss of the active cluster node in the primary datacenter. To see which cluster owns the cluster core resource, click on the cluster right under Failover Cluster Management and then expand Cluster Core Resources in the middle pane. Here you can see the current owner of the cluster core resource as shown in Figure 4. To force the cluster core resource online on the paused mode, right click on IP address assigned to the paused node and select Bring this resource online in the context menu.

Figure 4: Current owner of the cluster core resources
Although the passive node has been paused, when the active node went down the passive node became the current owner of the cluster/Exchange resources.
To bring the resources online, right-click on the passive node and select Resume in the context menu (Figure 5).
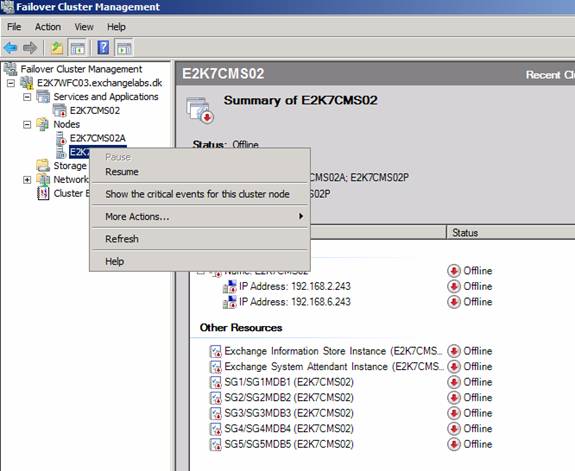
Figure 5: Resuming the cluster node
Now open the Exchange Management Shell and type the following command in order to bring the CMS online on the passive node:
Start-ClusteredMailboxServer <CMS Name>
The cluster and Exchange resources will now be brought online and Outlook clients will be able to re-connect to their mailbox.

Figure 6: CMS now online on the cluster node on the backup datacenter
How a Failover affects an Outlook 2007 User
Okay, so now that we have configured our multi-site CCR cluster according to best practice recommendations, let us try to simulate a failover of the CMS to the backup datacenter. Let us see how this affects Outlook users in the organization. In Figure 7 below, we have a screenshot of an Outlook 2007 client connected (in cached mode) to a mailbox stored on our CMS currently online on the cluster node in the primary datacenter.

Figure 7: Outlook client connected to a mailbox stored on our CMS currently online in the primary datacenter
Let us now move the CMS to the passive cluster node in the backup datacenter. We can do this using the following command:
Move-ClusteredMailboxServer <CMS> -TargetMachine < passive cluster node> -MoveComment Test

Figure 8: Moving the CMS to the passive cluster node in the backup datacenter
As can be seen in Figure 9 below, the CMS is now unavailable as it is currently being move to the passive cluster node in the backup datacenter.

Figure 9: Connection to Microsoft Exchange has been lost
When the CMS has been brought online, the DNS record must be updated with the IP address that was assigned to the CMS on the subnet in the backup datacenter. By default, this record has a TTL of 20 minutes. But as you saw earlier in the article, we changed the TTL value of the DNS record to 5 minutes. However this does not mean that Outlook will pick up the change after 5 minutes. Outlook client convergence is (10 minutes to issue update as a Windows 2008 multi-site cluster delays the record update to the DNS server by 10 minutes) + (DNS server replication latency) + (time remaining or full time in resolver cache for the TTL to expire), so expect between 10 to 30 minutes (the latter being large and/or slow environments with many DNS servers deployed).
The good thing is that when Outlook 2003/2007 is running in cached mode, the user can continue working and may not even notice that Outlook is offline. Also the end users don’t have to restart the Outlook client, it will re-connect automatically.
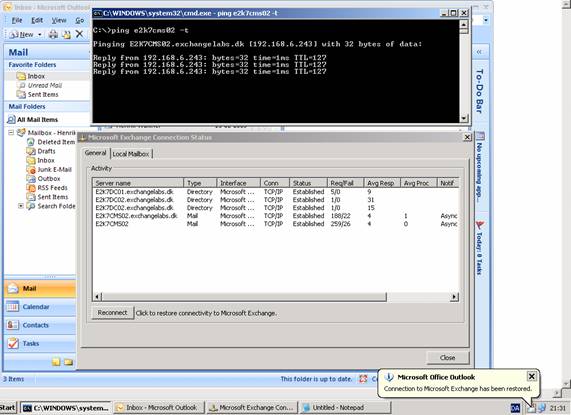
Figure 10: Connection to Microsoft Exchange has been restored
As most of you know, Outlook 2007 makes use of the availability/autodiscover service. After the failover, an Outlook 2007 client will simply pick a CAS server in the backup datacenter for availability/autodiscover service purposes.
In Figure 11 we can see that Outlook cannot contact to two CAS servers in the primary datacenters and fails over to the CAS server in the backup datacenter, when we test Autdiscover.
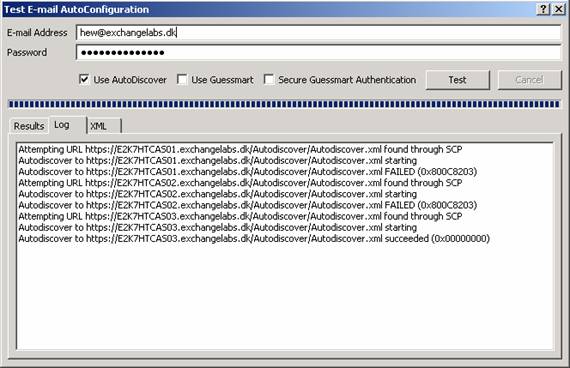
Figure 11: Testing Autodiscover to see if the CAS server in the backup datacenter is picked up
If you use Outlook 2003, then OAB and free/busy lookups relies on system folders in the Public Folder database. In case you have Outlook 2003 clients deployed, make sure you have a replica of the PF hierarchy in the backup datacenter.
Performing a backup in the backup datacenter
Another thing you should make sure is included in your disaster recovery plan is backup of the CMS in the backup datacenter. Are you ready for this once the CMS has failed over? I mean in worst case you just lost your primary datacenter and are currently captured in a site-level single point of failure scenario. This makes those database backups extra important as rebuilding the lost datacenter can take weeks even months depending on the damages.
Conclusion
As you have read throughout this article series, there are a lot of things to keep in mind when planning for deploying a multi-site CCR cluster. First thing you must decide is really whether this is the right choice for your organization. In most situations you should consider using SCR instead multi-site CCR clusters, but then again environments are different. Who knows, maybe you have a very specific reason to go for multi-site CCR clusters? And as mentioned in the introduction, multi-site CCR clusters can be a good solution if you have the right infrastructure and you deploy it properly.
Credits
I want to thank Tim McMichael (Enterprise Messaging Support Professional with MSFT) and Greg Taylor (Program Manager for the Exchange MCM/MCA program) for the great information they provided during the writing of this articles series.
If you would like to read the other parts of this article series please go to:



