Monitoring system activity and server performance is a necessary part of preventive maintenance for the server running Exchange 2000 Server. Through monitoring, you obtain data that you can use to diagnose system problems, plan growth, and troubleshoot problems. You can use the Exchange 2000 Monitoring and Status tool, diagnostic logging, extended logging, and Queue Viewer, to keep up-to-date on the status of your Exchange 2000 servers.
You can also use Windows 2000 tools such as Performance Monitor, Event Viewer, Task Manager, and Terminal Services Client, to ensure you have current information about how Exchange Server and the network are operating. Two additional services, Network Monitor and the DOS Network Diagnosis tool (Netdiag), provide additional network monitoring information.
Note Because of architectural differences between the monitoring user interfaces in Microsoft Exchange 5.5 and Exchange 2000 Server, mixed mode networks require that you use both monitoring systems. You can use the Exchange 2000 Server monitoring system to monitor Exchange 2000 Server only, and you can use the Exchange 5.5 monitoring system to monitor Exchange 5.5 only. However, when you are in native mode you can monitor by using only the Exchange 2000 Server monitoring system.
Exchange 2000 Monitoring Features
Exchange 2000 provides a number of features that assist you in monitoring and maintaining your Exchange server and network. These tools include the Monitoring and Status tool, extended logging and diagnostic logging.
Monitoring and Status Tool
The Monitoring and Status tool, located in the Tools folder in Exchange System Manager, is the primary Exchange 2000 tool you use to monitor the health and status of your servers. The tool is composed of two user interfaces: Notifications and Status.
Notifications
You can use the Notifications user interface with the Status user interface to set up e-mail alerts or script triggers when a warning or critical state is reached on any of your servers. In the Status user interface, you can configure warning and critical states for Simple Mail Transfer Protocol (SMTP) and X.400 queues, available virtual memory, CPU activity, and free hard disk space for an array of Microsoft Windows NT 4.0, Windows 2000, and Exchange 2000 services.
Configuring Warning and Critical States
You can configure Exchange to constantly monitor the performance levels of an array of network and application services. Levels for both warning states and critical states can be established so problems are announced and can be dealt with as they occur. Effective monitoring requires that you establish levels of acceptable performance for each resource. You can determine a warning threshold and a critical state threshold from this baseline level.
Exchange 2000 logs a critical state when any of the following default Microsoft Exchange Services stops running:
- Web Storage System
- Message Transfer Agent (MTA) Stacks
- Routing Engine
- System Attendant
- SMTP
- World Wide Web Publishing Service
To add a service to the default Microsoft Exchange Services
1. In the server’s Properties dialog box, click Detail on the Monitoring tab.
2. Select a service in the Default Microsoft Exchange Services dialog box.
3. Click Add, select the service you want to add, and then click OK.
You can add other services by performing the following steps.
To add a resource
1. In the server’s Properties dialog box, click Add on the Monitoring tab.
2. Select a resource from the list, and then click OK.
3. Configure the resource with the Warning state and Critical state thresholds in the Thresholds dialog box of the resource, and then click OK.
Note Any service that you add to the default Microsoft Exchange Services follows the same configuration rules as the default set. This means a critical error occurs if the selected service stops running. To add a set of services so a warning message rather than a critical error message occurs, you must create another set.
Note You use most of these services exclusively for troubleshooting. Many services start and stop frequently in normal operating conditions; therefore, you must think carefully before configuring Exchange 2000 to generate errors when a service stops running. Also, because monitoring and generating notifications consumes server resources, it is recommended that you do not configure Exchange 2000 to monitor an excessive number of services.
Configuring Notifications
Because you cannot instantly access all elements of every server, Exchange provides a Notifications tool that you can set to trigger a script or to alert appropriate personnel when Exchange crosses a warning or critical threshold.
Note Exchange 2000 is not configured by default to send notifications; all notifications must be configured through the user interface.
Status
The Status user interface allows you to view servers and connectors on your network with their status condition and administrative group designation. You can also disable all monitoring of a server through this user interface.
Monitoring the status of servers and connectors is one of the most effective ways to ensure that your network functions correctly. The status window of the Monitoring and Status tool shows the operating status of each server and connector on the network.
The following status states and definitions apply to servers:
- Available: Server online and functioning normally.
- Unreachable: One of the primary services on the server is down.
- Note If a server is unreachable and is in a different routing group, it may indicate that a connector between routing groups is down or does not exist.
- In Maintenance Mode: Monitoring is disabled on this server for maintenance, backup, repair, or another reason.
- Unknown: System Attendant cannot communicate with the local server.
The following status states and definitions apply to connectors:
- Available: Functioning properly.
- Unavailable: A communication function such as routing service is not functioning on this connector.
When you want to disable monitoring on a server for maintenance, backup, or recovery, select the Disable all monitoring on this server check box on the Monitoring tab of the Server Properties dialog box for an individual physical server.
Diagnostic Logging
You can use diagnostic logging in Exchange 2000 to monitor protocol connectors and Microsoft Exchange connectors. This is an effective way to keep up-to-date on a server’s status and to prevent potential problems. Diagnostic logging produces data about monitored connectors, which you can view using Event Viewer, one of the Windows 2000 Administrative Tools.
Exchange allows you to log diagnostic data by using the physical server’s Properties menu. On the Diagnostic Logging tab, select a service to monitor from the Services pane and one or more categories to monitor from the Categories pane.
Table: Services available for diagnostic logging
|
|
| Internet Message Access Protocol Version 4 (IMAP4) | IMAP4Svc |
| Lotus Notes GroupWise | LME-GWISE |
| Lotus Notes | LME-NOTES |
| Address List | MSExchangeAL |
| Lotus cc:Mail | MSExchangeCCMC |
| Microsoft Exchange Directory Synchronization | MSExchangeDX |
| Microsoft Exchange Schedule Plus Free/Busy | MSExchangeFB |
| Microsoft Exchange Router for Novell GroupWise | MSExchangeGWRtr |
| Information Store System | MSExchangeIS\System |
| Information Store Mailbox | MSExchangeIS\Private |
| Information Store Public Folders | MSExchangeIS\Public |
| Microsoft Mail | MSExchangeMSMI |
| MAPI Address Book Proxy Service | MSExchange NSPI Proxy |
| MAPI Address Book Referral Service | MSExchangeRFR Interface |
| Site Replication Service | MSExchangeSRS |
| SMTP Routing Engine and Transport | MSExchangeTransport |
| POP3 Protocol | POP3Svc |
You can configure logging levels for most services and categories. When a connector tries to send a log message, it first checks the logging level of the message against the logging level that is configured. If the logging level of the message is the same or higher than the logging level configured, the message is logged. Otherwise, the connector does not log a message and continues.
Logging level options are as follows:
- None: Only error messages are logged.
- Minimum: Warning messages and error messages are logged.
- Medium: Informational messages, warning messages, and error messages are logged.
- Maximum: Troubleshooting messages (fine and detailed information), informational messages, warning messages, and error messages are logged.
Note It is not recommended that you use the maximum logging setting because maximum logging considerably drains resources.
Protocol Logging Tool
The Protocol Logging tool provides detailed information about the commands being sent and received by SMTP and Network News Transfer Protocol (NNTP). This tool is particularly useful in monitoring and troubleshooting protocol or messaging errors.
The user interface for SMTP and NNTP logging is located in the Properties dialog box of an individual SMTP or NNTP virtual server.
To configure SMTP and NNTP logging
1. Select the Protocols folder, and then select either the SMTP or NNTP folder.
2. Right-click the virtual server. Exchange displays the Default Virtual Server Properties dialog box.
3. Select Enable Logging, and then click Properties.
Figure: General tab in the Extended Logging Properties dialog box
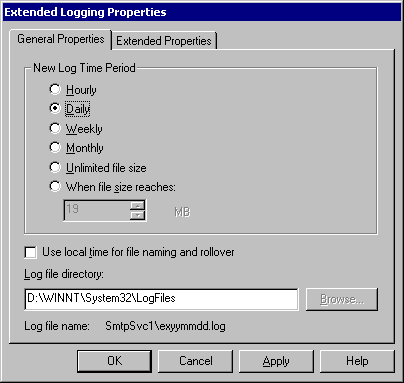
You can select the logging frequency and the name and location of the log file to create. To do so, click Properties on the General tab of the Default Virtual Server Properties dialog box. By default, the log file path is: Systemroot:\WINNT\System32\LogFiles
You can change the path or log file name by clicking one of the option buttons or by letting the current path stand as the default setting. You must select a logging format for the SMTP or NNTP log. By default, the log file name uses the following creation date for SMTP server: SmtpSvc1\exyymmdd.log.
Figure: Extended Properties tab in the Extended Logging Properties dialog box
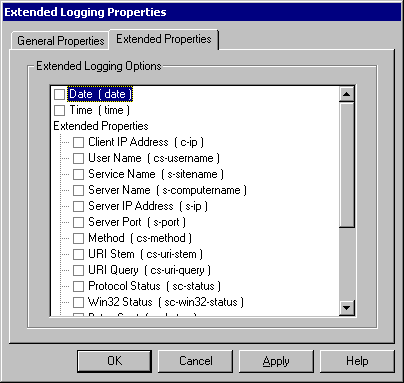
On the Extended Properties tab, you can select the configuration parameters from the Extended Logging Options pane. These logging options provide more detailed information on the Service and Category logging properties already configured for the virtual server. They do not add additional services or categories to be logged. Unlike the IMAP4 and POP3 protocol connectors and the MSExchange connectors, you cannot select the services and categories to log for SMTP or NNTP.
You can also establish a rollover time frame or file size using New Log Time Period on the General Properties tab in the Extended Logging Properties dialog box. When the time interval expires or when the log file reaches the set size, logs are overwritten.
Using Event Viewer to View Logs
Event Viewer is a Microsoft Management Console (MMC) snap-in that provides event information about running applications, the directory service, the file replication service, security, and the system. It also allows you to view the logs you configure for IMAP4 and POP3 protocol connectors and the MSExchange connectors. Events are logged by date, time, source, category, event number, user, and computer. By viewing the event data, you can see errors and warnings, and diagnostic information to find the problems that occur on any computer in the network.
You can see an event’s logging properties and text by viewing the properties of the event.
Queue Viewer
As part of the monitoring process, you can view the X.400 and SMTP queues, and other connectors that are installed on a server by using Exchange System Manager. You can use information such as message age and the number of messages in the queue to troubleshoot problems on a server.
You access the queues through three paths.
Figure: Paths to accessing queues
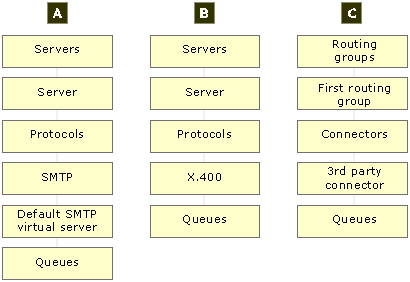
The two queues most useful to monitor are: Local Delivery and the Messages Awaiting Directory Lookup. A backlog in the Local Delivery queue indicates a problem with Web Storage System. A backlog in the Messages Awaiting Directory Lookup queue indicates there is a problem contacting the domain controller.
In addition, a backlog of messages with the same destination indicates there might be a problem with the destination domain controller.
Windows 2000 Performance Monitoring Tools
Exchange 2000 is integrally linked to Windows 2000, so many of the tools you use to monitor Exchange Server and the network are part of the Windows 2000 operating system. You can use the Windows 2000 tools Performance console, Netdiag, Task Manager, and Network Monitor to monitor performance.
Performance Console
System performance in Exchange is monitored in part by the Performance console, which includes System Monitor and Performance Logs and Alerts.
System Monitor
System Monitor displays graph, histogram, or report displays of system data. System Monitor provides short-term viewing of data, and information for troubleshooting and diagnosis. It includes tools such as physical hard disk counters and workload balance tools.
Performance objects that are associated with a resource or service that you can monitor contain at least one performance counter. You can view selected performance counters individually or in relation to other available counters.
Note Monitoring large numbers of counters can create overhead. To reduce this burden, you can either display data in report view when collecting information from a large numbers of counters, or direct data to a binary log or view the data in System Monitor as it is written to the log.
Performance Objects
When you monitor Exchange 2000 performance, you often rely on data contained in Windows 2000 performance objects, which is collected from components in your computer and monitored in Windows 2000 System Monitor and Performance Logs and Alerts. As a component functions in your system, it generates performance data. The data is formulated into performance objects that are typically named for the component generating the data. For example, the Processor object is a collection of performance data about processors on your system.
A range of performance objects is built into the Windows 2000 operating system and typically corresponds to the major hardware components such as memory, processors, and many more. Other applications might install their own performance objects as will happen with Exchange 2000.
Table: Exchange services or resources monitored using System Monitor
| Service or Resource to Monitor | Performance Object |
| Active Directory DXA Connector | MSExchangeADDXA |
| Address List | MSExchangeAL |
| Chat Communities | MSExchange Chat Communities |
| Chat Service | MSExchange Chat Service |
| Directory Service Access Caches | MSExchangeDSAccess Caches |
| Directory Service Access Contexts | MSExchangeDSAccess Contexts |
| Directory Service Access Processes | MSExchangeDSAccess Processes |
| Document Conferences | MSExchangeCONF |
| Document Conferencing Manager | MSExchangeDcsMgr |
| Document Conferencing Protocol (Multipoint Control Unit) | MSExchangeT.120 |
| Epoxy Queues and Activity | EXIPC |
| Event Store | MSExchangeES |
| File Replication Connector | FileReplicaConn |
| File Replication Settings | FileRepSet |
| HTTP Extension | Exchange Server HTTP Extension |
| Internet Information Server Store Driver | Exchange Store Driver (IIS) |
| Internet Message Access Protocol Version 4 | MSExchangeIMAP4 |
| Web Storage System | MSExchangeIS |
| Private Information Store | MSExchangeIS Mailbox |
| Public Information Store | MSExchangeIS Public |
| System Information Store | MSExchangeIS |
| Mailbox Information Store | MSExchangeIS Mailbox |
| Public Folders Information Store | MSExchangeIS Public |
| Lotus CC Mail | MSExchangeCCMC |
| Lotus Notes Message Center | MSExchangeNMC |
| Message Transfer Agent | MSExchangeMTA |
| Message Transfer Agent Connections | MSExchangeMTA Connections |
| MS Mail Connector Interchange | MSExchangeMSMI |
| Exchange Referral Service | MSExchangeSA-RFR |
| MS Mail Connector Mail Transfer Agent | MSExchangePCMTA |
| Name Service Provider Interface (Active Directory Integration) | MSExchangeSA-NSPI Proxy |
| Network News Transfer Protocol Commands | NNTP Commands |
| Network News Transfer Protocol Server | NNTP Server |
| Novell Groupwise Connector | MSExchangeGWC |
| Object Linking and Embedding database events | MSExchangeOledb Events |
| Object Linking and Embedding database resources | MSExchangeOledb Resources |
| Post Office Protocol Version 3 | MSExchangePOP3 |
| Service Account | MSExchangeSA |
| Site Replication Service | MSExchangeSRS |
| Simple Mail Transfer Protocol | SMTP |
| Store Driver | Exchange Store Driver (Store) |
| Video Conferencing | MSExchangeIPConf |
| Web Mail | MSExchangeWebMail |
Each Exchange 2000 performance object has at least one associated counter, which you can configure to monitor instances involving any number of server actions. For more information about the function of a counter for a specified performance object, click Select Counters from List, select a counter, and then click Explain.
Physical Hard Disk Counters
Statistics about hard disk drive usage help you balance the workload of network servers. System Monitor provides physical hard disk counters for troubleshooting, capacity planning, and measuring activity on a physical hard disk.
At a minimum you need to monitor the following counters:
When testing hard disk performance, you can log performance data to another hard disk or computer so it does not interfere with the hard disk you are testing.
You might want to observe additional counters, such as:
The PhysicalDisk\ Avg. Disk sec/Transfer counter reflects how much time a hard disk takes to fulfill requests. A high value may indicate the hard disk controller is continually retrying the hard disk because of failures. These failures increase average hard disk transfer time.
You can also check the value of PhysicalDisk\ Avg. Disk Bytes/Transfer. A value greater than 20 KB indicates the hard disk is performing well. Low values result when an application accesses a hard disk inefficiently. Because hard disk counters can cause a modest increase in hard disk access time, Windows 2000 does not automatically activate the counters at system startup.
Logical Disk Counters
Performance data about the logical hard disk is not collected by the operating system by default. To obtain performance data for logical drives or storage volumes, you must type diskperf –yv at the command prompt. This causes the hard disk performance statistics driver, which is used for collecting hard disk performance data, to report data for logical drives or storage volumes. Windows 2000 uses the diskperf –yd command to obtain physical drive data.
Determining Workload Balance
To balance loads on network servers, you need to know how busy the server hard disks are. You can determine this by using the PhysicalDisk\ % Disk Time counter, which indicates the percentage of time a drive is active. If the results of PhysicalDisk\ % Disk Time is high (more than 90 percent), you can check the PhysicalDisk\ Current Disk Queue Length counter to see how many system requests are waiting for hard disk access. The waiting input/output (I/O) requests should be sustained at a number no more than 1.5 to 2 times the number of physical hard disk spindles.
Most hard disks have one spindle, although redundant array of independent disks (RAID) devices usually have more. A RAID device appears as one physical hard disk in System Monitor. RAID devices created through software appear as multiple drives (or instances). You can either monitor the physical hard disk counters for each physical drive (other than RAID), or you can click All Instances on the Add Counters dialog box to monitor data for all of the computer’s drives.
Use the values of the PhysicalDisk\ Current Disk Queue Length and PhysicalDisk\ % Disk Time counters to detect bottlenecks in the hard disk subsystem. If the PhysicalDisk\ Current Disk Queue Length and PhysicalDisk\ % Disk Time values are consistently high, consider upgrading the hard disk or moving some files to an additional hard disk or server.
The system maps physical drives to logical drives using the same instance name. Therefore, if you have a dynamic volume that consists of multiple physical hard disks, instances might appear as Disk 0 C:, Disk 1 C:, and Disk 2 D:, (where C: is made up of physical drives 0 and 1). If you have two logical partitions on a hard disk, the instance appears as 0 C: D:.
For hardware-enabled stripe sets, statistics for each hard disk are not available. You can obtain this data only when monitoring stripe sets enabled in software.If you use a RAID device, the PhysicalDisk\ % Disk Time counter can indicate a value greater than 100 percent. If this happens, use the Avg. Disk Queue Length counter to determine the average number of system requests waiting for hard disk access.
Performance Logs and Alerts
Performance Logs and Alerts contain features for logging counter and event-tracing data, and for generating performance alerts.
With counter logs, you can:
Trace logs record data when an event such as a hard disk I/O error or page fault occurs. When the event occurs, the monitoring service sends the data to the log service.You can set an alert that sends a message, runs a program, or starts a log when a selected counter’s value equals, exceeds, or falls below a specified setting.
When you select a tool to see its status, if any logs or alerts are defined, then they appear in the details pane. A sample settings file for a counter log named System Overview is included with Windows 2000 and appears in the right pane of the Performance console when you select Counter Logs under Performance Logs and Alerts. You can use this file to see basic system data such as memory activity, hard disk activity, and processor activity.You can right-click the log icon to create a new log or alert in a new file, or you can use settings from an existing HTML file as a template.
Task Manager
Task Manager provides information about processes, memory usage, and processor performance statistics. However, it lacks the logging and alert capabilities of the Performance console and does not provide the breadth of information available from System Monitor counters.
Monitoring Processes
To use Task Manager to monitor a process, click the Task Manager’s Processes tab to see a list of processes that are running and information about their performance. Task Manager process tables include all processes that run in their own address space, including all applications and system services. Exchange 2000 runs two processes you can view using Task Manager: Store.exe and Inetinfo.exe.
Note Even if you have more than one virtual server running on a server, only one instance of Store.exe and Inetinfo.exe exists.
Monitoring the System
To use Task Manager to see a dynamic overview of system performance, including a graph and numeric display of processor and memory usage, click the Performance tab in the Windows Task Manager dialog box.To graph the percentage of processor time in privileged or kernel mode, on the View menu, click Show Kernel Times. This is a measure of the time that applications take to operate system services. The remaining time, known as user mode, is spent running threads in the application code.If you use multiprocessor computers, on the View menu, select CPU History, and then view the non-idle time of each processor in a single graph or in separate graphs.
Terminal Services Client
The Terminal Services Client user interface, located in Windows 2000 Administrative Tools, allows you to log on to a remote computer from another terminal. You can use this user interface to perform remote administration and monitoring of any accessible server on the network.
For example, if you are in Toronto and you discover that a server in Tokyo is not responding and you cannot contact the on-site administrator, but the server has Terminal Services Client installed, you can remotely log on to the computer and administer it. You can restart it, run installed applications, start and stop services, and monitor performance.
Another benefit of Terminal Services Client is that you can run applications that are not installed on your computer by gaining access to a computer with Terminal Services Client that has the application you want to run.
Network Monitor
Monitoring a network typically involves observing resource usage on a server and measuring network traffic. You can use Network Monitor to understand the traffic and behavior of your network components. Unlike System Monitor, which you use to monitor hardware and software, Network Monitor exclusively monitors network activity.
Observing Resource Usage
To check resource usage, start by tracking the counters on your server. To focus on network resource usage, monitor the counters that correspond to the various layers of your network configuration. Abnormal network counter values often indicate problems with a server’s memory, processor, or hard disks. For this reason, the best approach to monitor a server is to watch network counters with the following performance counters: Processor\ % Processor Time, PhysicalDisk\ % Disk Time, and Memory\ Pages/sec.
If a dramatic increase in pages per second is accompanied by a decrease in total bytes per second handled by a server, the computer probably lacks physical memory for network operations. Most network resources, including network adapters and protocol software, use non-paged memory. A computer can page excessively if most of its physical memory is allocated to network activities, which leaves a small amount of memory for processes that use paged memory. To verify this usage, check the computer’s system event log for entries indicating it is out of paged or non-paged memory.
Measuring Network Traffic
You can use Network Monitor to observe throughput across network layers. Investigating network performance includes monitoring activity at different network layers. There are four layers in which you monitor network activity: the data-link layer, the network layer, the transport layer, and the presentation or program layer.
Data-Link Layer
The data-link layer includes the network adapter. Use the following network user interface object counters to monitor network activity at the data-link layer:
Network Layer
Use the Internet Protocol (IP) object counters to monitor network activity at the network layer:
Transport Layer
The transport layer varies with network protocol in use. For TCP/IP, use the TCP object counters to monitor network activity at the transport layer:
If the retransmission rate is high, this may indicate a hardware problem. The Internet Control Message Protocol (ICMP) and User Data Protocol (UDP) object counters are useful for more extensive monitoring of TCP/IP network transmissions. The ICMP performance object consists of counters that measure the rates at which ICMP messages are sent and received by using the ICMP protocol. It also includes counters that monitor ICMP protocol errors. The UDP performance object consists of counters that measure the rates at which UDP datagrams are sent and received using the UDP. It includes counters that monitor UDP errors.
Presentation/Program Layer
For the presentation/program layer, use the Server object counters if you monitor a server, or the Redirector object counters if you monitor a client computer. Exchange 2000, as well as some program-layer processes such as Web servers, has its own object counters that you use to monitor transmissions across this layer. The Redirector object counters collect data about requests transmitted by the Workstation service. The Server object counters collect data about requests received and interpreted by the Server service. At a minimum, you should include the Total Bytes Per Second counter for both the Redirector object (for client computers that you monitor) and the Server object (for server computers).
Each of these objects provides several other counters that you might want to monitor if you suspect problems with either the Workstation or Server services:
The Sessions Errored Out counter reports automatic disconnections and sessions that end because of an error. For more accurate values for sessions that end because of an error, obtain the value for sessions timed out and reduce the Sessions Errored Out value by that amount.
Network Diagnosis Tool
You can use the Network Diagnosis tool (Netdiag), a Windows 2000 support tool, to diagnose problems on a network. This command-line diagnostic tool helps isolate networking and connectivity problems by performing a series of tests to determine the state of your network client. These tests, and the network status information they provide, give you a more direct means of identifying and isolating network problems.
Analyzing Performance Data
Performance monitoring concentrates on how the operating system and any applications or services use the resources of the system, such as the hard disks, memory, processors, and network components.The data you accumulate through daily monitoring provides you with the information you need to analyze trends and plan your system capacity. Even if your system operates satisfactorily today, it is important to plan for changes in demand caused by new users or by technologies and programs that you deploy. Unanticipated network growth can result in overused resources and poor levels of network service. By characterizing system performance over time, you can justify the need for new resources before the need becomes critical. The following are some definitions to help you understand performance-monitoring terminology.
Throughput is a measure of the work done in a unit of time, typically evaluated from the server side in a client/server environment. Throughput tends to increase as the load increases, up to a peak level. It then begins to fall, and a queue might develop. Throughput in an end-to-end system, such as client/server, is determined by how each component performs. The slowest point in the system sets the throughput rate for the system as a whole. Often this slow point is referred to as a bottleneck. Performance monitoring identifies where bottlenecks occur in your system. The resource that shows the highest use is often the bottleneck, but not always. The bottleneck can also be a resource that successfully handles a great deal of activity. There is no bottleneck if no queues develop.
A queue is a group of jobs that are waiting to run. A queue can form under a variety of circumstances. A queue can develop when requests come in for service by the resource at a faster rate than the resource’s throughput, or if requests demand more time from the resource than the system can handle. A queue can also form if the requests occur at random intervals, such as large batches at the same time. When a queue becomes long, work is not handled efficiently and you might experience delays in response time.
Response time is the time required to do work from start to finish. In a client/server environment you typically measure response time on the client side. Response time generally increases as the load increases. You can measure response time by dividing the queue length for the resource by the resource throughput.
Establishing a Baseline
When you collect performance data over a period of time, with data reflecting periods of low, average, and peak usage, you can make a subjective determination of what is acceptable performance for your system. That determination is your baseline, which you can then use to detect bottlenecks or to watch for long-term changes in usage patterns that require you to increase capacity.
One of the goals of monitoring Exchange 2000 is to locate problems or anomalies in the server or network. To do this, you establish a baseline by collecting performance and diagnostic data over an extended period during varying types of workloads and user connections. A performance baseline is a range of measurements that represents acceptable performance under typical operating conditions. This baseline provides a reference point that makes it easier to notice problems before they become serious.
When you need to troubleshoot system problems, performance data gives you information about the behavior of system resources at the time the problem occurred, which is useful in discovering its cause.When determining your baseline, it is important to know the types of work that are done and the days and times when work is done. This helps you associate work with resource usage and determine whether or not performance during those intervals is acceptable.
If you find that performance diminishes somewhat for a brief period at a given time of day, and you find that many users are logging on or off at that time, it might be an acceptable slowdown. Similarly, if you find that performance is poor every evening at a certain time and you can tell that this time coincides with nightly backups when no users are logged on, performance loss might be acceptable.
Analyzing Results
The baseline you develop establishes the typical counter values you expect to see when your system performs satisfactorily. However, you need guidelines to help you interpret the counter values and eliminate false or misleading data that might cause you to set target values inappropriately. You need to identify and investigate bottlenecks to analyze your results and take action.
When you collect and evaluate data to establish a valid performance baseline, you should:
- Investigate zero values or missing data.
Watching for Large Values
You need to watch for values that are unusually large for one instance and not another when you are monitoring processes that have the same name. This can occur because System Monitor sometimes misrepresents data for separate instances of processes of the same name by reporting the combined values of the instances as the value of a single instance. Tracking processes by process identifier can help you solve this problem.
Including Thread Identifiers
When you are monitoring several threads and one of them stops, the data for one thread might appear to be reported for another. This is because of the way threads are numbered. If you begin monitoring and have three threads—numbered 0, 1, and 2—and one of them stops, then all remaining threads are sequenced again. This means the original thread 0 no longer exists and the original thread 1 is renamed 0. As a result, data for the stopped thread 0 can be reported along with data for the running thread number 1 because old thread number 1 is now old thread number 0. To solve this problem, you can include the thread identifiers for the process in your log or display. You can use the Thread/Thread ID counter for this purpose.
Ignoring Occasional Spikes
You do not need to place too much importance on occasional spikes in data. These spikes might be due to the startup of a process and, if so, they are not an accurate reflection of counter values for that process over time. The effect of spikes can remain over time when using counters that average.
Using Graphs for Reporting
When you monitor performance over an extended period of time, you need to use graphs. Reports and histograms show only last values and averages, and they might not give an accurate picture of values.
Excluding Startup Events
Unless you specifically want to include startup events in your baseline, you must exclude them because they are temporary high values that tend to skew overall performance results.
Investigating Zero Values or Missing Data
Zero values or missing data can impede your ability to establish a meaningful baseline. You should investigate the source of these issues and obtain the missing data, if possible, before you attempt to establish a baseline.
Identifying and Investigating Potential Bottlenecks
Deviations from your baseline provide the best indicator of performance problems. However, as a secondary reference, the table, describes recommended thresholds for object counters. You can use this table to help identify when a performance problem is developing on your system.
Table: Recommended thresholds for object counters
| Resource | Object\Counter | Recommended Threshold | Comments |
| Hard disk | LogicalDisk\ % Free Space | 15 percent | None |
| Hard disk | LogicalDisk\ % Disk Time | 90 percent | None |
| Hard disk | PhysicalDisk\ Disk Reads/sec, PhysicalDisk\ Disk Writes/sec | Depends on manufacturer’s specification | Check the specified transfer rate for your hard disks to verify that this rate does not exceed the specifications. Some SCSI disks can handle 50 to 70 I/O operations per second. |
| Hard disk | PhysicalDisk\ Current Disk Queue Length | Number of spindles plus 2 | This is an instantaneous counter; observe its value over several intervals. For an average over time, use PhysicalDisk\ Avg. Disk Queue Length. |
| Memory | Memory\ Available Bytes | Less than 4 MB | Research memory usage and add memory if needed. |
| Memory | Memory\ Pages/sec | 20 | Research paging activity. |
| Network | Network Segment\ % Net Utilization | Depends on type of network | You must determine the threshold based on the type of network you use. For example, for Ethernet networks, 30 percent is the recommended threshold. |
| Paging File | Paging File\ % Usage | More than 70 percent | Find the process that is using a high percentage of processor time. Upgrade to a faster processor or install an additional processor. |
| Processor | Processor\Interrupts/sec | Depends on processor | A dramatic increase in this counter value without a corresponding increase in system activity indicates a hardware problem. Identify the network adapter or hard disk controller card causing the interrupts. You might need to install an additional adapter or controller card. For current CPUs, use a threshold of 1,500 interrupts per second. |
| Server | Server\ Bytes Total/sec | If the sum of bytes total/sec for all servers is roughly equal to the maximum transfer rates of your network, you might need to segment the network. | |
| Server | Server\ Work Item Shortages | 3 | If the value reaches this threshold, consider tuning the InitWorkItems or MaxWorkItems entries in the registry (in HKEY_LOCAL_MACHINE\SYSTEM\ CurrentControlSet\Services\lanmanserver\ Parameters). |
| Server | Server Work Queues\ Queue Length | 4 | If the value reaches this threshold, there might be a processor bottleneck. This is an instantaneous counter; observe its value over several intervals. |
| Multiple Processors | System\ Processor Queue Length | 2 | This is an instantaneous counter; observe its value over several intervals. |
Caution Do not use a registry editor to edit the registry directly unless you have no alternative. The registry editor bypasses the standard safeguards provided by administrative tools. These safeguards prevent you from entering conflicting settings or settings that are likely to degrade performance or damage your system. Editing the registry directly can have serious, unexpected consequences that can prevent the system from starting and require that you reinstall Windows 2000. To configure or customize Windows 2000, you must use the programs in Control Panel or MMC wherever possible.
Investigating performance problems should always start with monitoring the system before looking at individual components. In precise terms, a bottleneck exists if a particular component’s limitation keeps the entire system from performing quickly. Therefore, even if one or more components in your system are heavily used, if other components or the system as a whole show no adverse effects, then there is no bottleneck.
Factors that cause bottlenecks include the number of requests for service, the frequency at which requests occur, and the duration of each request. As long as these factors are perfectly synchronized, queues do not develop and bottlenecks do not occur. The device with the smallest throughput is typically the primary source of a bottleneck.
It is difficult to detect multiple bottlenecks in a system. You might spend several days testing and retesting to identify and eliminate a bottleneck, only to find that another bottleneck appears in its place. Only thorough and patient testing of all elements can ensure that you have found all of the problems.
It is not unusual to trace a performance problem to multiple sources. Poor response time on a workstation is most likely the result of memory and processor problems, while servers are more susceptible to hard disk and network problems.
Problems in one component might be the result, rather than the cause, of problems in another component. For example, when memory is scarce, the system moves pages of code and data between hard disks and physical memory. The memory shortage becomes evident from increased hard disk and processor use, but the problem is the lack of memory, not the processor or hard disk.



