by Andy Syrewicze, Microsoft MVP, VMware vExpert and Technical Evangelist at Altaro
It’s somewhat surprising to me, even to this day, how many IT pros and purchasing managers look at a line item on a piece of paper and think to themselves, “all deduplication technologies are created equal.” I suppose in the early days of the technology that was true, but just like any feature in IT, things change. Developers create new functions, features, and innovations, and that process applies to deduplication as well. There are perhaps few areas of data storage that are more important than your backup storage, so that’s how we’re going to be looking at deduplication in this article today — through the prism of storing backups.
When I have this conversation with IT pros I always seem to fall back onto four main points as to why having quality dedupe in your backup environment matters. Yeah, I could probably go into more than that, but generally, most points seem to fall into one of the following categories:
– Deduplication storage savings and efficiencies
– Dedupe performance implications
– Safety of data
– Dedupe targets
Each point is important, and they aren’t necessarily ranked in order of importance. However, I’d like to cover each point individually. So, let’s take a look.
Deduplication storage savings and efficiencies
This is likely what most people will think of when I mention the word deduplication. Reducing storage footprint is, in fact, the primary function of deduplication technologies. In short, if you think about the fact that there will be similar data across your organization getting backed up and stored, storing it twice doesn’t make a lot of sense, right? Dedupe’s purpose is to find this similar data and make sure only one copy is kept and discards the rest. What’s important, however, is how this process occurs.
File-based deduplication
Older deduplication methods were file-based. They would query individual files on a filesystem and based on the info retrieved, would make sure an identical file doesn’t get stored a second time. However, file-based deduplication isn’t that efficient. Much of a file can be identical to other files on a system even though the file is named differently, has a different time-stamp, or contains some other file-level difference that would necessitate it being marked as unique. You’ll find that because of this, a lot of data is going to be saved more times than it really needs too because the deduplication engine isn’t smart enough to really understand the data itself. This is where block-level deduplication entered the picture.
Block-level deduplication
Block-level deduplication gets underneath files. It looks at the raw blocks of data on the filesystem themselves. In doing so it can more accurately understand the type of data contained within a given block without having to worry about the overall “file” that a given block is part of. What this amounts to in terms of storage is a more accurate detection of similar data, resulting in more space saved on the backup target. As an example of this, I’ve included a breakdown of how this process works in our own backup application, Altaro VM Backup. From left to right, you can see how the blocks are first broken down within a virtual machine (VM) and then across other VMs before ultimately being compressed and stored.
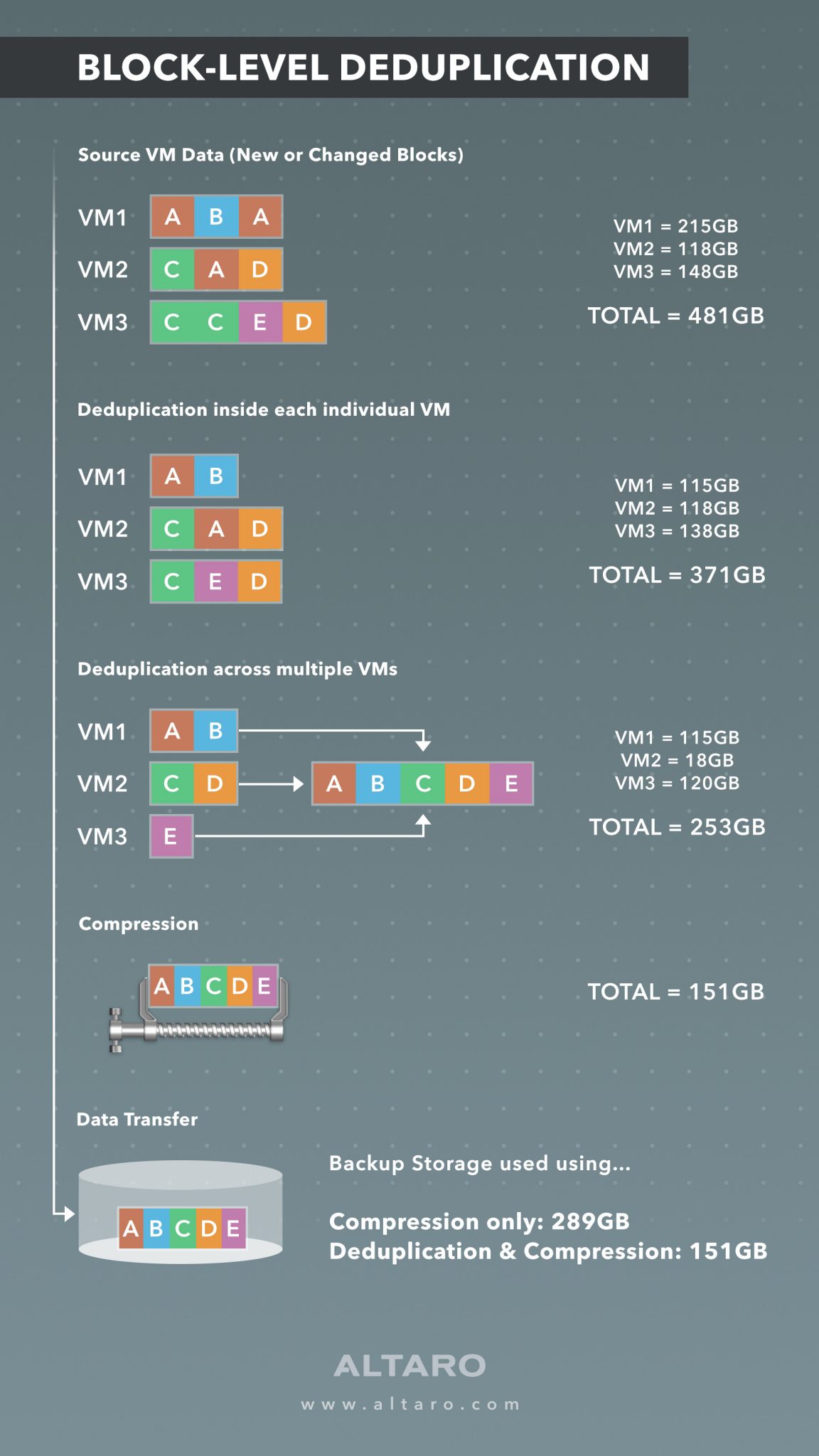
This method not only ensures best-of-breed backup storage savings within a given VM, but across all VMs being backed up, allowing you to back up more, and more often before having to purchase more storage.
Dedupe performance implications
The other side of the “deduplication coin” is performance. Early versions of deduplication technologies were resource-intensive. The added disk thrashing often wasn’t worth the storage savings. This was due to a variety of reasons. File-based dedupe requires more system cycles than block-level dedupe, so just by using a block-level deduplication technology, you’re putting yourself ahead of the game. However, another thing to watch for is where in the process does the deduplication occur? It usually boils down to two options:
Post-process deduplication
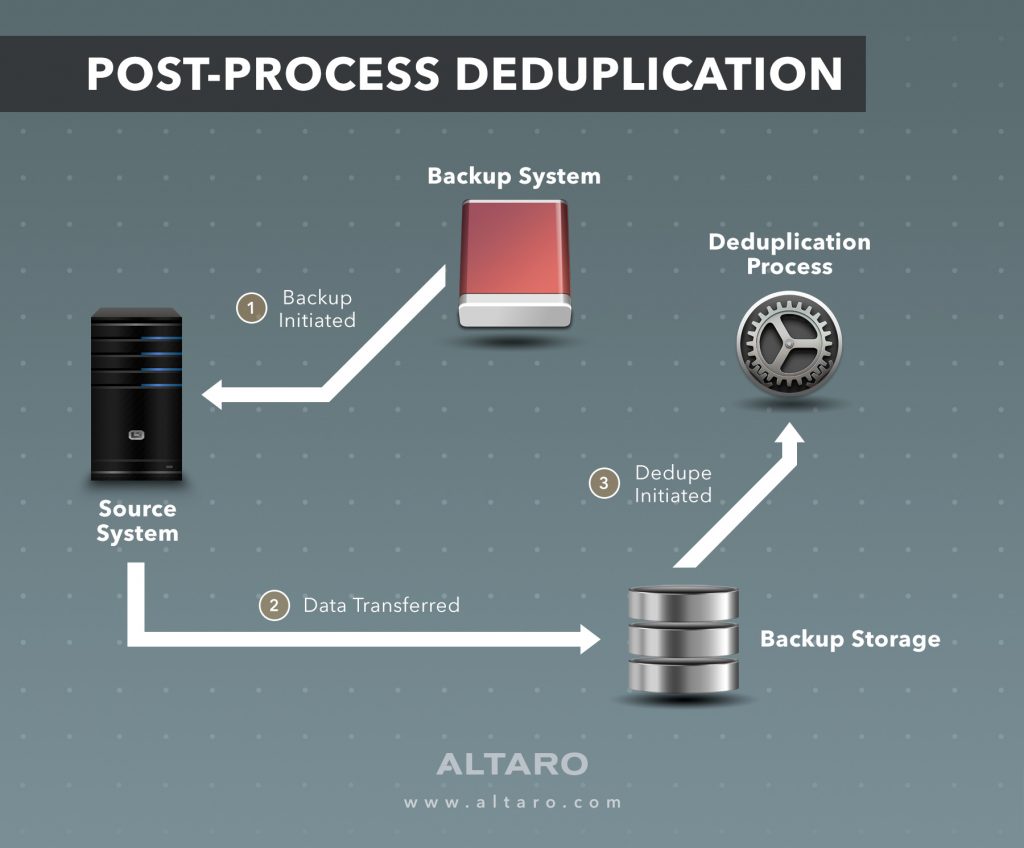
Post-process deduplication is the act of deduping the payload after it’s been copied to the backup storage. Think back to how unfriendly old dedupe technologies were on system load. The thought process here was to get the data copied (similar data included) as soon as possible so the production servers and backup system weren’t bogged down with the process. After the copy job, a secondary appliance or server would then parse all the data and dedupe it within the storage location.
There have been a number of issues with this approach. For starters, you’re copying data multiple times that doesn’t need to be copied. Secondly, you’re adding complexity to your environment with the requirement of having an appliance or dedicated hardware to do this post-process deduplication. This is where inline dedupe comes in.
Inline deduplication
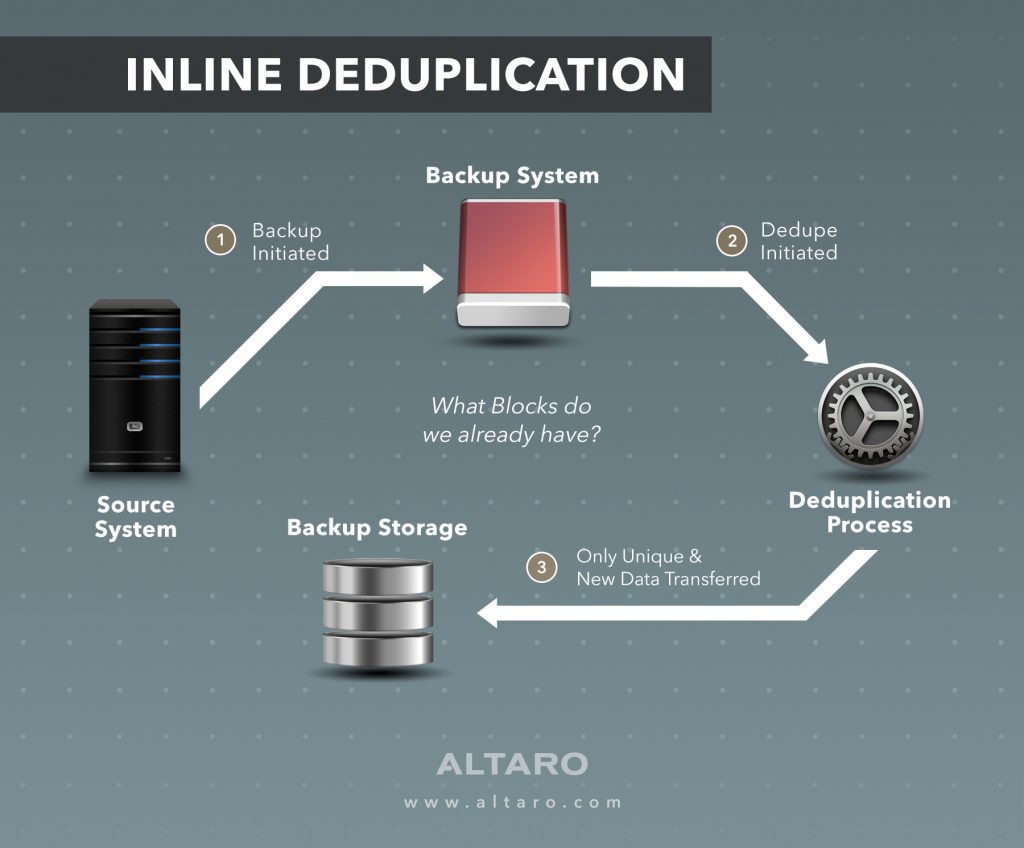
Inline deduplication is more intelligent in that it will first use a combination of features to determine before the copy-process what blocks actually need to move across the wire. For example, Altaro VM Backup keeps a database of protected blocks. It’s basically a list of blocks that have already been backed up. When a backup process occurs this database is queried, and if a block is new, it gets sent across the wire to the backup storage. If it is not new, the backup process disregards it and life goes on.
This method serves to not only make sure unique data is protected, but it also ensures that backup times are short. The process has gotten so efficient that it requires less time to do it in this manner than to simply copy the payload and dedupe later.
Safety of data
This really goes without saying, but you want a deduplication technology you can trust to not damage your data. When you have an automated system deciding what data stays and what data goes, you want to make sure it’s quality software. Most dedupe engines are doing their own internal sanity checks, but whichever deduplication technology your backup software uses, you need to check a few things on your own to be on the safe side:
- There is a data health-check process running on a regular basis.
- This health-check process should be self-healing if possible.
- All protected blocks should be recoverable from all defined times within the retention period.
- Regular recovery testing should be scheduled and automated to ensure data viability.
Following these bullet points will help you keep tabs on data health after the dedupe process and make sure it isn’t inadvertently damaging your backup data.
Proper deduplication targets
This may seem like a silly one, but really what it comes down to is a question. Does the dedupe look for like blocks within a single system or within the storage location? If it’s a within a single system, you’re still storing similar data across multiple systems. If your dedupe engine runs at the storage-target level, then it’s deduping blocks across all data stored within that location. The latter is obviously the most efficient, and this is the way that Altaro VM Backup will function. Whichever vendor you’re using, you want to make sure they’re using this method as well for maximum efficiency.
Ask the right questions
As you can see, there are many questions to ask about your deduplication choice. All of these questions add up to a deduplication engine that:
– Provides more storage efficiencies
– Doesn’t monopolize system resources
– Ensures data safety
– Dedupes similar data across workloads
By leveraging a good choice in this technology area, you’ll ultimately be able to do more with less, keep your production systems happy while using it, and have fewer headaches throughout the process. As stated, having quality deduplication matters.
Bonus (if you want the best deduplication for your virtual environment)
So many Altaro VM Backup users have already saved on storage thanks to the Augmented Inline Deduplication feature. Check out what they have to say here and if you want to see how well Altaro VM Backup’s Augmented Inline Deduplication will work for you too, download your free 30-day trial of Altaro VM Backup today.



