If you would like to read the other parts in this article series please go to:
- Managing small virtual environments (Part 1) – The Basics
- Managing small virtual environments (Part 2) – Busting Myths
- Managing small virtual environments (Part 4) – The Players
Introduction
In part 1 of this series, you learned about some of the basics behind virtualization and why even small organizations should consider either getting into virtualization or expanding their virtualization efforts. You also learned about how some common arguments against virtualization can be refuted.
In this, part 2 of this series, you learned about some virtualization myths and why they are mostly busted.
In this, part 3 of this series, you’ll learn about some of the high level concepts and features that are found in virtualized environment. This will prepare you for the next two parts of this series, in which you will learn about virtualization licensing and get a comparison matrix of the major hypervisors.
Abstraction
In part one of this series, I described virtualization as being all about workload abstraction. What this actually means is that virtualization provides administrators with an opportunity to decouple resources from one another and to decouple application workloads from hardware.
In traditional server environments, an administrator installs an operating system onto a server and, then, on top of that operating system, installs various applications to support the needs of the business. Over time, administrators have found that this model is incredibly inflexible. It becomes exceedingly difficult to perform even basic functions, such as migrating to a new physical server once the hardware reaches an end-of-life status.
In virtualized environments, a hypervisor software layer is inserted between the hardware and the operating system, as shown in Figure 1 below.
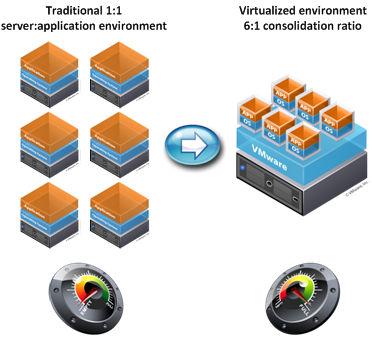
Figure 1: How virtualization changes the computing paradigm
In Figure 1, in the diagram to the left you see a traditional technology environment in which the operating system and application are installed directly on the hardware. Once this is done, consider these elements “glued” together. While it’s possible, it can sometimes be tough to tear these elements apart when necessary.
Now, look at the right-hand side of the diagram. Here, a hypervisor—in this case, VMware—has been inserted between the hardware and the individual workloads running on the hardware. With the hypervisor in place, administrators can create any number of virtual servers that run right on top of the hypervisor. The hypervisor provides these virtual machines with access to all of the hardware that’s necessary to operate.
Moreover, the hypervisor doesn’t have any glue. In fact, it almost has Teflon sprayed on it. With hypervisors running on multiple physical servers, administrators can slide workloads off of one host server and to a different host server without connected users ever being aware that a migration took place.
And therein lies the true value of workload abstraction.
As you replace hardware, it’s just a few clicks of the mouse and your applications are running on your new server. No pain, no fuss.
In Figure 1, you also see another benefit of virtualization: Resource usage. In the left-hand diagram, each of the six running workloads requires only minimal processing power. In other words, there is a whole lot of wasted CPU in the environment that is rarely, if ever, actually necessary. In the figure to the right, those same workloads now run on a single server. Resources are used much more wisely in the figure to the right, leading to overall lower costs.
Resource pooling
So how does virtualization actually work its magic? You saw in Figure 1 that there are now six workloads running on just one host. The way it works is this: The hypervisor takes a look at the resources—RAM, storage and processors—that it has available and places those resources into a pool. Now, when an administrator creates a virtual machine, he simply allocates resources from this shared pool and assigns them to the new virtual machine.
With a single physical server running a hypervisor, this ability to make better use of the server’s physical resources is the only real benefit that you can get from a hypervisor, and, to be certain, it’s a big benefit.
When individual host servers—all running hypervisors—are brought together, the administrator is creating a cluster that further extends the capabilities of the hypervisors on the individual servers. Now, the hypervisors can interact with one another. Further, when coupled with the right management software, the resources present on each of the individual servers become available to all of the hosts in the cluster.
Again, with the right management software, this aggregate resource pool can then be leveraged to enable the environment to start making decisions about where new workloads should be housed. As administrators start to create virtual machines in such an environment, in many cases, the administrator doesn’t make a decision as to which host will house the new workload. Instead, the management software analyzes the environment, analyzes the resource needs of the new host and, based on available resources, simply places the workload on the host that it feels is most appropriate at the time.
Abstraction + Resource Pooling + Multiple Hosts (Cluster)
This is where things start to get really interesting in the world of virtualization and organizations start moving beyond simple server consolidation projects and embracing the virtual environment for its benefits. With the creation of a cluster that consists of multiple hosts, workload abstraction, management and availability are taken to whole new levels.
Now, rather than workload abstraction simply being used to help run many workloads on one server, administrators can just move entire virtual machines from one host to another. Better yet, today’s hypervisors and management suites can work this sorcery in ways that are completely transparent to the user.
This kind of capability enables new use cases, which include:
- Automated failover. The hypervisor’s management software keeps constant watch on every workload in the environment. Suppose a host fails. The management software can be instructed to simply restart the failed workloads on another host in the cluster. While users will notice a short outage, this is a far better scenario than waiting for an IT staffer to notice that a server is down.
- Load balancing. One of the promises of virtualization has always been the ability to make very efficient use of the server’s resources. Rather than running a single workload that hardly uses the processor, for example, organizations can harness that excess computing power and run many workloads on a single server. With multiple servers in a cluster, the hypervisor management software can watch running workloads and, as virtual machines get busier and need more resources, automatically move those virtual machines to hosts that may have more available resources. This is all handled with administrator intervention, meaning that the environment remains relatively simple to manage.
Different hypervisor products have different names for their individual workload migration features. In VMware vSphere, the name vMotion is used. In Microsoft’s Hyper-V, it’s called Live Migration and in Citrix’s XenMotion.
There are different kinds of workload migration available to you, too.
Move a virtual machine’s running state
In many environments, the virtual environment uses some kind of shared storage. In these environments, all of the servers in a cluster can see the same storage. This is one of the reasons that workloads can be migrated between hosts so easily. All of the hosts can see the storage, so moving a running virtual machine consists of moving just what’s in the hosting server’s memory to the target host. While the underlying mechanics are incredibly powerful and incredibly complex, the administrator is shielded from that complexity and is able to concentrate solely on the workload.
Move a virtual machine’s stored files
In organizations with multiple storage options, you can move a virtual machine’s files from one storage device to another while leaving the virtual machine itself running on the original host.
Of course, you can always move a virtual machine to both new storage as well as a new hosts.
The method by which this takes place is somewhat different depending on the hypervisor in use. You will learn about the specific feature names and methods later in this series.
Summary
Now that you understand the workload abstraction and management options at your disposal, you can start taking a look at specific products to begin to get a picture for how the features in each product align to these concepts. In Part 4, we’ll start to look at specifici products.
If you would like to read the other parts in this article series please go to: