If you would like to read the other parts in this article series please go to:
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 2)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 3)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 4)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 5)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 6)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 7)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 8)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 9)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 10)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 11)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 12)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 13)
Introduction
Just as many of us became relatively comfortable with deploying highly available (and often site resilient) Exchange 2007 based messaging solutions, the Exchange product team released Exchange 2010. Fortunately though, the Exchange 2010 high availability story is exactly the same as with Exchange 2007 right? Hey, didn’t I start with this introductory line in another multi-part article? Well, I think I did but it fits well for this multi-part article as well.
As you probably noted by reading the title, the main focus here will be on medium organizations. I will take you through how you plan and deploy an Exchange 2010 site resilient solution using four Exchange 2010 servers. I’ll then simulate a site failure in order to show you the steps necessary to bring the messaging solution into a fully functional state in the other datacenter. I mean how good is it to have a site resilient solution if you don’t understand the failover steps required if one of the datacenters becomes a smoking hole?
Site Resiliency in Exchange 2007
When it came to designing a resilient mailbox design in the Exchange 2007 days, most of the large organizations used an active/passive or active/active datacenter model where they achieved local high availability within a datacenter using cluster continuous replication (CCR) based clustered mailbox servers. That is they deployed both cluster nodes in a CCR cluster in the same primary datacenter which meant that fail or switchovers (*overs) didn’t force clients to try connect to the other datacenter.
Standby continuous replication (SCR) was then used to make the solution site resilient by replicating log files from the CCR based clustered mailbox server (SCR source servers) to one or more clustered SCR target servers deployed in the other active or passive datacenter. When a disaster took down the primary datacenter, the clustered mailbox servers (CMS) was then brought online on the standby clusters (SCR targets) in the other datacenter.
Load balancing and high availability for the Client Access server (CAS) role within a datacenter was usually achieved using either Windows Network Load Balancing (WNLB) or a load balancer solution from a 3rd party vendor. With Exchange 2007 most went with WNLB (including Microsoft IT). I uncover this approach here. If Exchange 2007 was deployed across multiple datacenters each with their own Internet connection, the recommended approach in regards to the Client Access server role was to use a unique namespace for each datacenter (for instance mail.contoso.com and mail.standby.contoso.com). In case of a disaster that results in the primary datacenter to become unavailable, the external and internal DNS records for client access was pointed to CAS servers in the failover datacenter.
Resiliency was designed into the Hub Transport role so that Hub Transport server to Hub Transport server communication inside an organization automatically load balances between available Hub Transport servers in an Active Directory site. In order to load balance inbound SMTP connections from external SMTP servers/clients, internal LOB application, and devices such as miscellaneous network devices you could use WNLB or a load balancer solution from a 3rd party vendor (I cover the WNLB approach here). For inbound SMTP traffic from external servers/clients, you could also use the good old MX record trick which I describe in my Edge Transport server article series (more specifically part 6). During a failover from one datacenter to another, mail flow could be redirected to the other datacenter by changing the MX record or the cloud-based service such as FOPE to point at the Hub Transport or Edge Transport servers in the failover datacenter.
Many medium didn’t have the budget needed for local high availability based on CCR combined with site level mailbox resiliency via SCR. Instead some of these organizations deployed a multi-site CCR cluster (like covered here) often without knowing the exact pros and especially cons of doing so. Others simply made the decision to not provide local mailbox resiliency and instead deployed an Exchange 2007 multi-role (with mailbox, Client Access, and Hub Transport roles) in each datacenter. They then enabled SCR, so that databases were replicated to the other Exchange 2007 server.
This scenario is shown in Figure 1 below. Since no Windows Failover clustering based functionality was used in the design, they could use Windows Server 2003/2008 standard edition and as long as they stayed on or under 5 databases, they could even archive mailbox resiliency using Exchange 2007 standard edition.
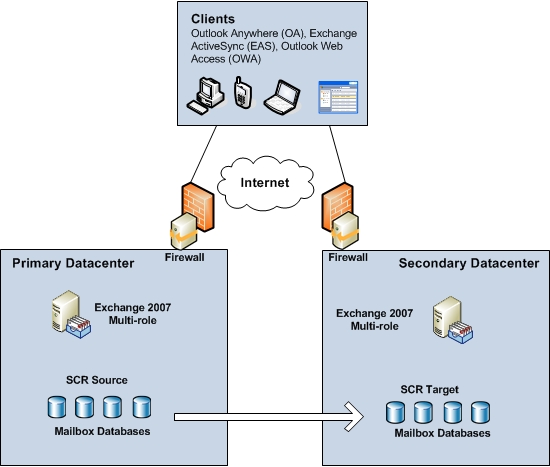
Figure 1: Site resiliency in the Exchange 2007 days
Although this solution was ideal when it came to keeping the number of Exchange servers required down to a minimum, it’s important to stress out that the solution had no real high availability on the mailbox level (other than RAID on the storage level). Instead this solution was really a disaster recovery solution more than it was a high availability solution as it required several manual steps to switch or failover to the secondary datacenter. But it gave the organizations a warm feeling when it came to the protection of mailbox data and because of the number of required Exchange servers; it was a relatively inexpensive solution. On top of that this many organizations virtualized the Exchange 2007 solution.
Sidebar
Most of you probably are aware of the fact that I already uncovered new high availability related improvements and changes such as RPC CA arrays, hardware load balancing, high availability using DAG and even a multi-part article which describes the different most common site resilient solutions available with Exchange 2010.
Here’s a list of them:
- Designing a Site Resilient Exchange 2010 Solution
- Uncovering the new RPC Client Access Service in Exchange 2010
- Load Balancing Exchange 2010 Client Access Servers using an Hardware Load Balancer Solution
- Uncovering Exchange 2010 Database Availability Groups (DAGs)
If you haven’t yet read them, now would be a good time to do so before you read on.
Site Resiliency in Exchange 2010
As Exchange 2010 began to see the light it became obvious that it was difficult to compete with the above solution not in terms of functionality but price. This is because we with Exchange 2010 no longer have the concept of SCR. Instead an Exchange 2010 solution must use DAG and DAG requires the Windows Failover Clustering component which means the Windows Server 2008/2008 R2 enterprise edition in required in order to replicate databases between the datacenters.
When it comes to customers that consider moving from an Exchange 2007 based solution where CCR based clustered mailbox servers are used, things look significantly better though. Because as you probably know, when going with CCR it required a minimum of 4 Exchange 2007 servers in each datacenter in order to archive redundancy on all levels, since you aren’t allowed to install other Exchange server roles than the mailbox server role on the cluster nodes.
However, with Exchange 2010 we can install the other Exchange server roles (except the Edge Transport role) on a server that is part of a DAG. This is really interesting since it help us to keep the number of required Exchange servers down. Some of you may say yes but I heard you cannot combine Windows Network Load Balancing (WNLB) and DAG on the same server correct? Yes this is correct. So if I cannot combine WNLB and DAG, I’m still forced to deploy a minimum of four servers in each datacenter right? No not necessarily, because this is where hardware-based or virtual load balancing solutions comes into the picture. Yeah right you say, I’ve already checked the prices of several LB solutions and I don’t like what I see. Well, my answer to this is you looked at the wrong vendor prices since you can get a pair of midmarket hardware load balancers for approximately $3000 dollars which compared to 2 x Windows Server 2008 R2 standard edition and 2 x Exchange 2010 standard edition licenses is a very affordable price. In addition, hardware or virtual load balancers from a third party vendor gives you so much more than what WNLB can offer (for details see my hardware load balancing articles series). In addition, remember you can use much cheaper storage for Exchange 2010 databases than what was the case with Exchange 2007. 7200 RPM Enterprise SATA disks are more than sufficient for storing mailbox data because of significant store schema optimizations that were done with Exchange 2010.
To achieve load balancing and high availability for the Client Access server (CAS) services within a datacenter, we used a load balancing solution from a 3rd party vendor.
Like in Exchange 2007, resiliency has been designed into the Exchange 2010 Hub Transport role, so that Hub Transport server to Hub Transport server communication inside an organization automatically is load balances between the Hub Transport servers in an Active Directory site. In order to load balance inbound SMTP connections from external SMTP servers/clients, internal LOB application, and devices such as miscellaneous network devices, I use the third party load balancers.
So an Exchange 2010 solution that need to provide both local HA and site level DR in a medium sized organization could look something like this:
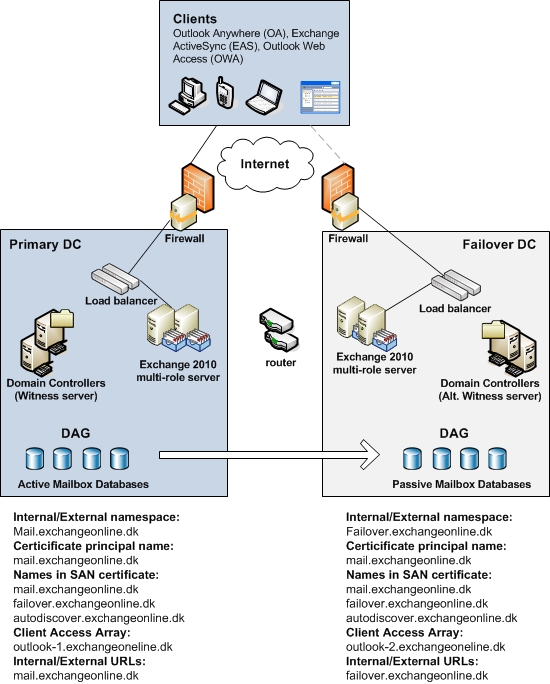
Figure 2: Site Resiliency in Exchange 2010 (active/passive datacenter model)
With this scenario it’s expected the organization only have active users in one of the datacenters. Note that a different namespace is used for each datacenter and both datacenters have Internet connectivity. Because we don’t have active users in both datacenters at the same time, we only have one DAG.
If the organization needs to have active users in each datacenter, the solution would instead look something like this:
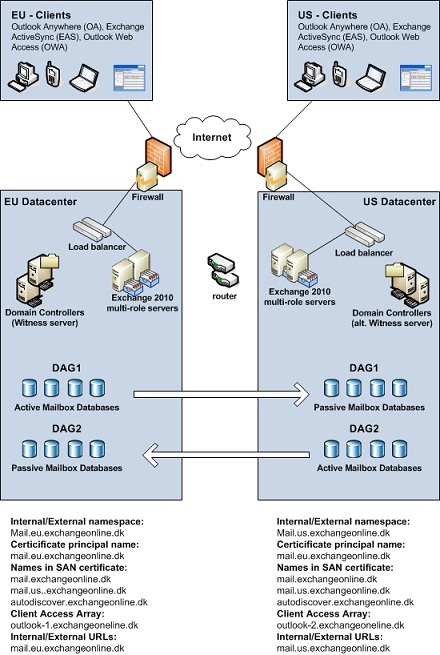
Figure 3: Site Resiliency in Exchange 2010 (active/active datacenter model)
With this scenario the organization have active users in both datacenters. Note that a different namespace is used for each datacenter and both datacenters have Internet connectivity. Because we have active users in both datacenters at the same time, we use two DAGs. This is in order to avoid the situation where the WAN connection between the datacenters is down and only users in one site have mailbox access.
Okay so these are the two scenarios I’ll uncover in detail over the next coming parts. Before we end this part, let’s take a look at the lab environment I used for writing this up. It consists of the following:
- 1 x Windows Server 2008 R2 Active Directory forest (Exchangeonline.dk)
- 2 x virtual datacenters/locations
- 2 x AD sites (one in datacenter 1 and one in datacenter 2)
- 2 x subnets in datacenter 1 ( MAPI network: 192.168.2.0/24 & replication network: 10.10.10.0/24)
- 2 x subnets in datacenter 2 ( MAPI network: 192.168.6.0/24 & replication network: 10.10.11.0/24)
- 4 x Exchange 2010 multi-role servers (2 in datacenter 1 and 2 in datacenter 2)
- 1 x member servers in datacenter 1 (will be configured as witness server)
- 1 x member server in datacenter 2 (will be configured as alternate witness server)
- 4 x Domain Controllers (2 in datacenter 1 and 2 in datacenter 2)
- 2 Load balancers (1 hardware based LB in datacenter 1 and 1 virtual LB in datacenter 2)
- 1 virtual router with 4 interfaces (2 x MAPI and 2 x replication)
There you go. Part 1 of this multi-part article ends here.
If you would like to read the other parts in this article series please go to:
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 2)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 3)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 4)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 5)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 6)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 7)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 8)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 9)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 10)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 11)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 12)
- Planning, Deploying, and Testing an Exchange 2010 Site-Resilient Solution sized for a Medium Organization (Part 13)



