The world is changing, and if you are still working with just IaaS (infrastructure-as-a-service), you are missing out on a lot of new stuff such as PaaS (platform-as-a-service) and the real revolution on application development — microservices. If you don’t want to become the last gunslinger (I had to reference “The Dark Tower” by Stephen King) and be left behind by a world to that has moved on, it is time to refresh your skills and see how new applications are being developed and configured as containers in a cloud age. And a good launching pad in any discussion of Kubernetes for IT pros is with the components that make up the architecture.
We went through Docker and containers in some of my previous articles here at TechGenix. Here is a list of them to give you an idea where we are coming from, and they will set the tone for this article:
- Getting started with containers
- Windows Server containers
- Creating Docker images
- Using Dockerfile to create Docker images
We will be talking about Azure Container Services (AKS) in an upcoming article, but in this article, we are going to cover the basics of Kubernetes components to give an overview of the architecture of the solution. Keep in mind that Kubernetes is one of the most active community projects and it is dynamic. Features are being added in increased velocity to support the ever-increasing need of the community, enterprises, and cloud providers that offer Kubernetes-as-a-service.
The first concept that any IT pro has to understand about Kubernetes is that it is an excellent orchestrator, and it is de facto standard when we need automation of containers to deliver fast and reliable applications. Microsoft Azure and the other major cloud providers have it on their service portfolio.
Kubernetes was developed initially by Google, and they donated it to the community as open-source. Kubernetes will use the container solution that you have installed on your server, and due to its architecture, it integrates with other tools/components through APIs, including load balancers, storage, etc.
Kubernetes for IT pros: High-level overview
The beauty of Kubernetes for IT pros is that the architecture is relatively simple, and it does a great job keeping the cluster and containers in check throughout their lifecycle. Kubernetes is always validating the current status of the cluster and making sure that changes are made to bring it to the desired state. It is a constant battle to make sure that everything is working as it should, but the most important thing is that Kubernetes does that without human intervention most of the time.
The Kubernetes administrator provides the desired state by sending requests to Kubernetes using manifest files, which are YAML files. Although Kubernetes behind the scenes processes JSON files, the administrator will create the desired configuration using YAML files. The YAML files are simple to use, and most humans can read and understand because they are intuitive.
It would be impossible to describe the entire Kubernetes in a single article. The goal of this article is to show the high-level architecture of the product and some core concepts. If you are interested, the community uses Kubernetes.io as the source for all documentation about the product, and it is an excellent starting point to learn Kubernetes!
Kubernetes high-level architecture
Kubernetes has two distinct roles: master and worker. We can (and we should) have more than one server for each role to provide high availability and redundancy. The following diagram (Sorry for some of the icons, my Visio stencil has only Azure objects) depicts the roles and interaction between master and worker roles.

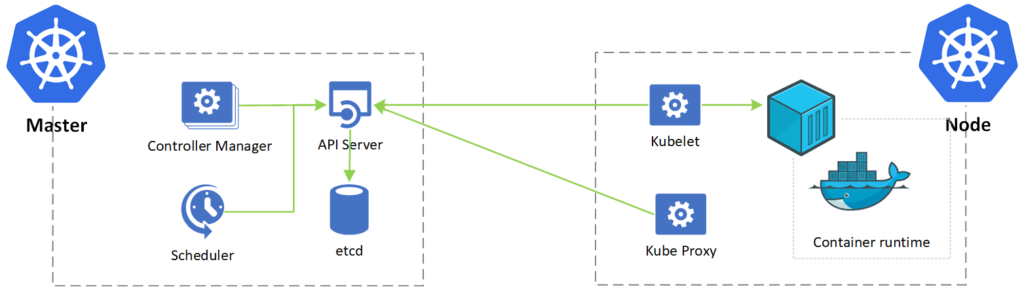
The master role is the brains of the operation, and it is comprised of four components: API Server, Scheduler, etcd, and Controller Manager.
- API Server (Kube-apiserver): It is the public relations of Kubernetes. The vast majority of the Kubernetes roles communicate with the API Servers. This component is accessible from the management tools (kubectl) and is similar to the Azure Resource Manager (ARM) concept for Azure administrators.
- Scheduler (Kube-scheduler): The logistic role. Every time a new application or demand is requested, this role will select which nodes will make it happen based on a series of logic built-in in to the role.
- etcd: It is the database (key pair store) that has all the information about the workloads that are declared to the Kubernetes cluster.
- Controller Manager (Kube-controller-manager): a series of small controllers that are always running and performing actions to make sure that we are close to the desired state of the cluster.
The other role in our story is the node role. That is the role where the work is done, meaning your future containerized applications will be running on a node role. The node role has three components: kubelet, proxy, and container runtime.
- Kubelet: This is the Kubernetes agent that communicates with the API server to provide information and status about its health and retrieve jobs to be performed.
- Proxy (Kube-proxy): This is responsible for the networking routing and IP addresses that are assigned to pods and services.
- Container Runtime: This is the connection with the container solution on the host. We will be using Docker moving forward.
Kubernetes architecture: Communication flow
We have covered the roles and their components. It is time to tackle how they communicate with each other. Kubernetes makes our lives much more comfortable because the API server is the central role, and the vast majority of communication among components has the API server as a target.
The following diagram shows the communication architecture of Kubernetes, and it helps when troubleshooting and trying to understand the solution from a bird’s-eye view.
Kubernetes and high availability
When planning to run your own Kubernetes cluster on your servers, the Kubernetes administrator must be aware of how to make the solution and its roles high available to avoid a single point of failure. When using Microsoft Azure, the master roles are provided by the platform, and there is no need to worry about the resiliency and high availability of those components.
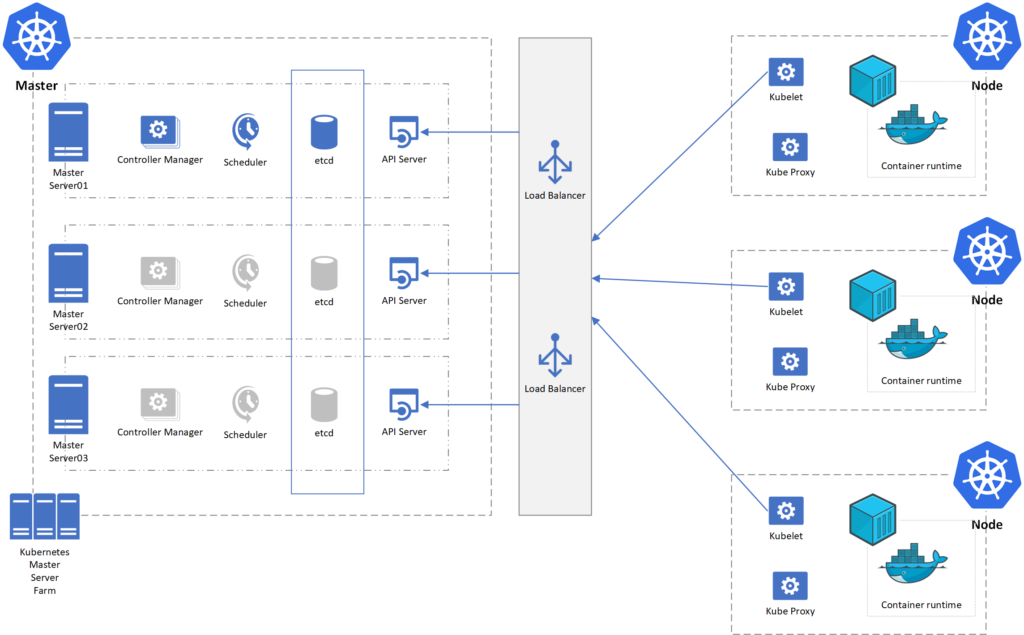
The goal in this section is to show how a simple high available of the roles would work to provide resiliency.
We should start with a minimum of three servers, where five servers could be the sweet spot to allow two hardware failures without impacting the environment. (This math is based on the etcd component.)
The API server will be active in all instances, and the only requirement is to have a load balancer in front of it. The API server role is stateless. Therefore, Kubernetes components and node agents can talk to any server at any given time.
The etcd component is different from all other components. All instances of the database will be replicated. It will have a single master, which will receive all writes and reads, and the data will be replicated to the remaining etcd instances. All communication within the master node will occur at the local etcd database.
All other components of the Kubernetes ecosystem will have one active instance at any given time. A three-node cluster of the master role architecture would be similar to the image depicted below.
Kubernetes for IT pros: So much more to talk about
We will be doing more on Kubernetes for IT pros, so keep checking TechGenix for updates!
Featured image: Shutterstock / TechGenix photo illustration



